
China AI System #4: China’s Token Exports Are Exploding—What Does It Mean for Hyperscalers?
Chinese LLMs are taking over OpenRouter’s weekly leaderboard, Inference demand is booming overseas—and the meter likely runs on AWS, GCP, and Azure.

This is part of China AI System, a series on how China is turning AI from a model race into an industrial system—where compute, deployment, capital discipline, and market scale compound into industrial advantage. I track the mechanics of China’s AI buildout: inference economics and cost compression, the stack from chips to clouds to apps, the adoption flywheels across industries and consumer products, and the global pathways through which value—and the profit pool—are captured.
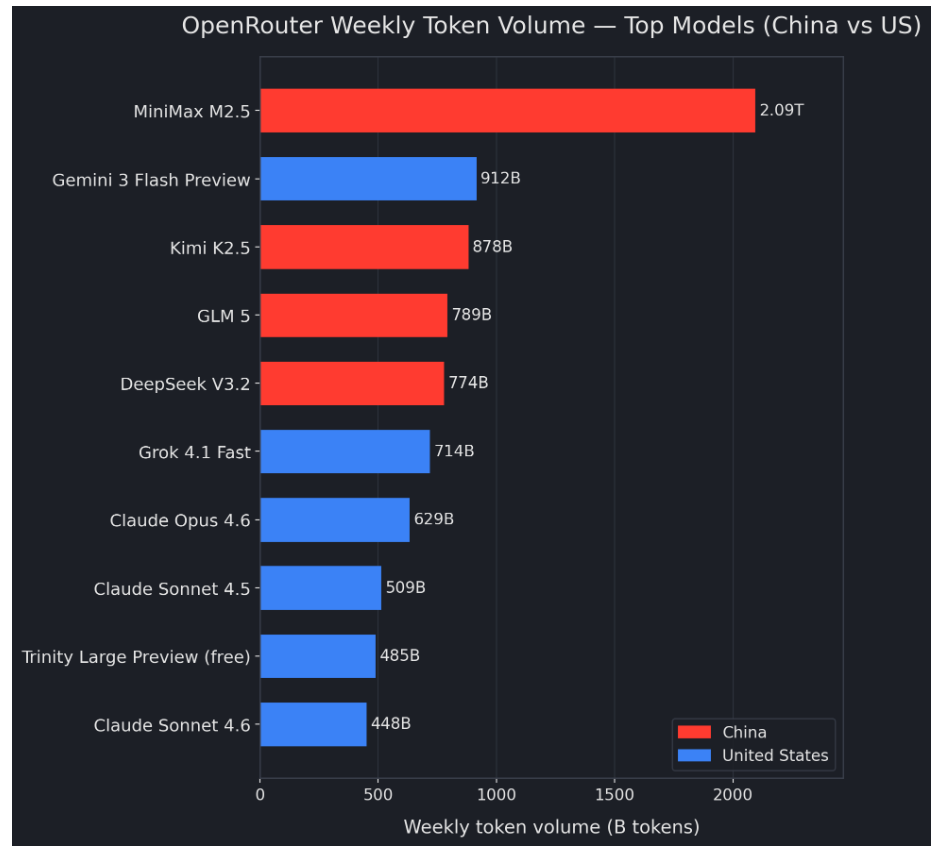
A quick glance at OpenRouter’s rankings for the past week reveals a striking pattern: Four of the top five models by weekly token volume are Chinese: MiniMax M2.5 (~2.09T tokens), Moonshot’s Kimi K2.5 (~878B), Zhipu/GLM 5 (~789B), and DeepSeek V3.2 (~774B). The only non-Chinese model in the top five is Google’s Gemini 3 Flash Preview (~912B). Expanding to the top ten, those four Chinese models together account for ~4.53T tokens, which is more than half of the top-10 total (~8.23T tokens).
When a weekly leaderboard is effectively “occupied” by Chinese models, the instinctive question is obvious: does this mean Chinese LLMs are moving beyond the domestic market and beginning to squeeze U.S. closed models on the inference side? But the more important question comes right after it: where is this demand actually happening—inside China, or being absorbed at scale outside China?
1. Chinese LLMs token exploding does not mean the profit pool sits in China
OpenRouter’s 100T-token study offers a counterintuitive but more explanatory answer: mainland China is not the primary consumption base for this token surge. By billing region, China accounts for only 6.01% of tokens.
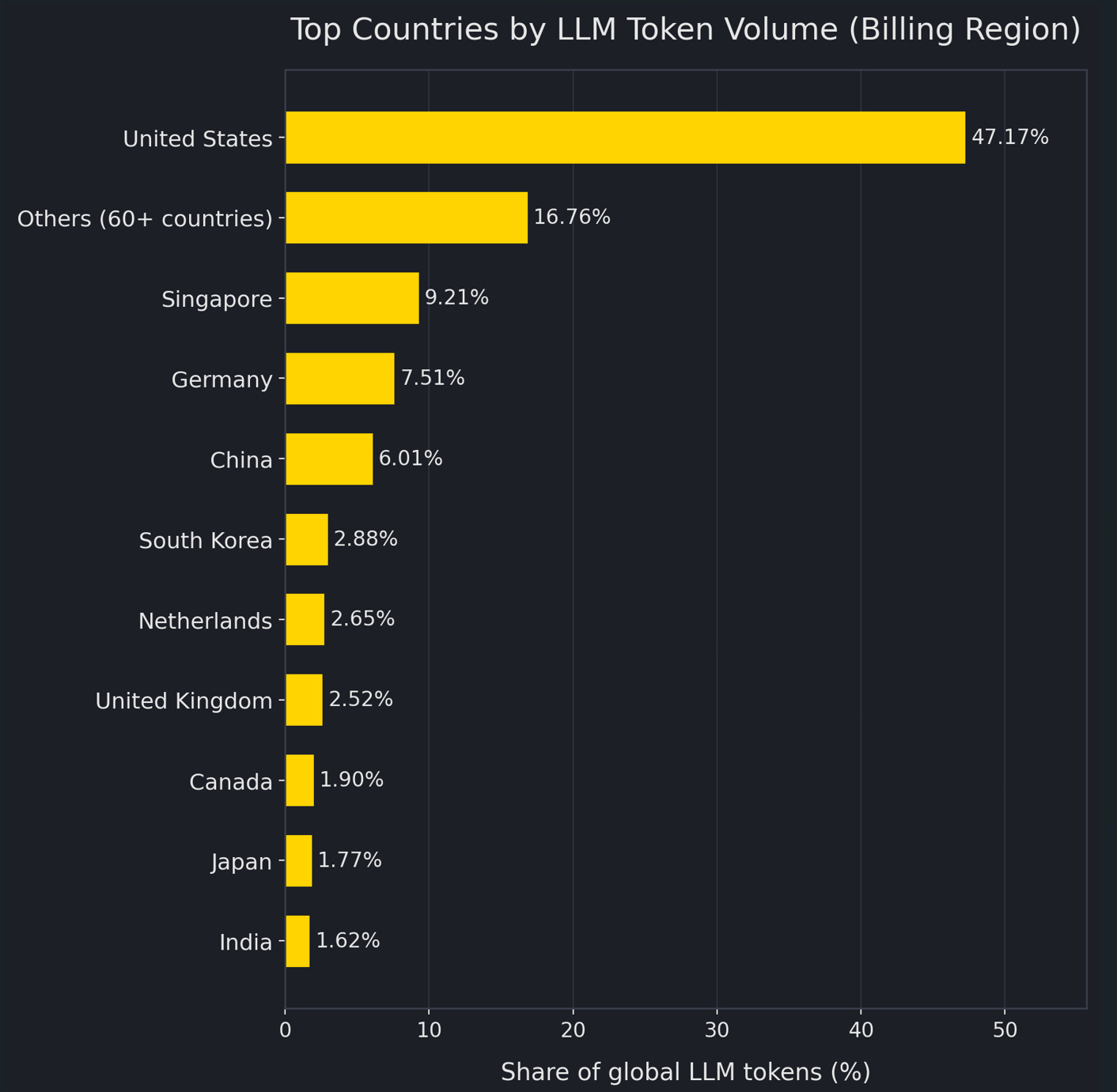
And by detected prompt language, Simplified Chinese accounts for only 4.95%. By contrast, the United States alone represents 47.17% of tokens by billing region; North America is 47.22% in aggregate; Europe is 21.32%. Even more telling, Singapore accounts for 9.21%—higher than China—suggesting that token “geography” often reflects where corporate accounts and payment entities are domiciled, not where the model is trained or where the user physically sits.
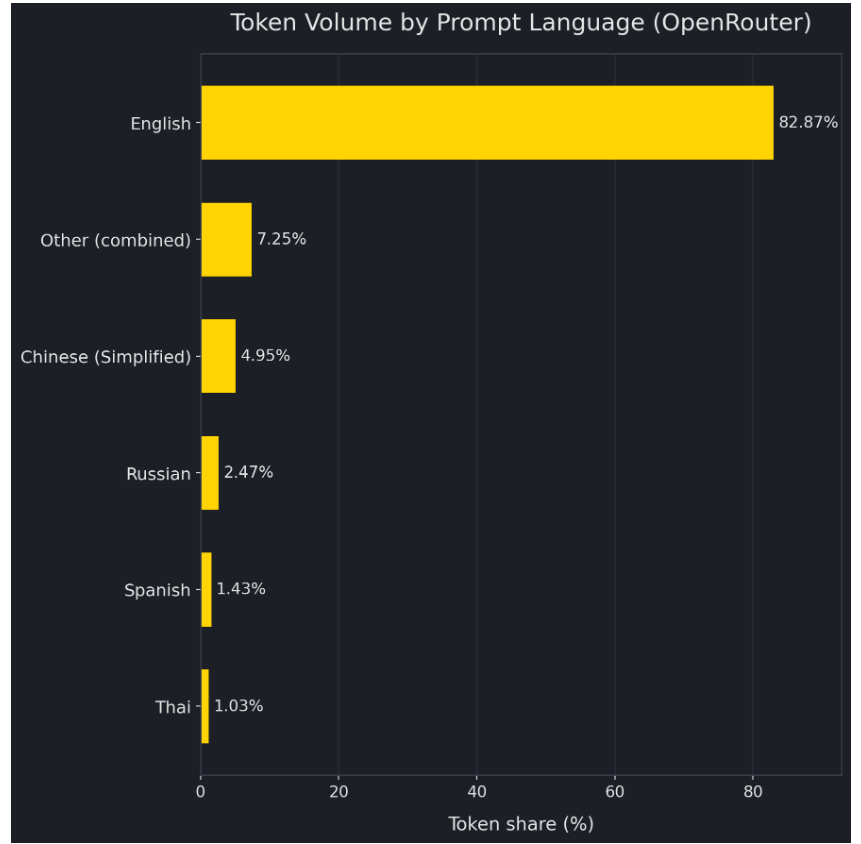
Put the two sets of facts together and the structure becomes clear: Chinese models dominate the weekly leaderboard, yet China itself contributes only ~5–6% of token volume (whether measured by billing region or by Chinese language). Where does the gap come from? It almost has to come from non-China billing systems—most plausibly North America, Europe, and cross-border billing hubs like Singapore. In other words, this looks less like a “domestic craze” and more like overseas throughput.
More concretely, if mainland China contributes only ~5–6% of total token volume, while Chinese open models represent roughly ~20% on average over the past six months, then token consumption of Chinese open models outside China would be on the order of ~15% of global tokens. Put differently, overseas consumption of Chinese open models is roughly ~3x domestic consumption.
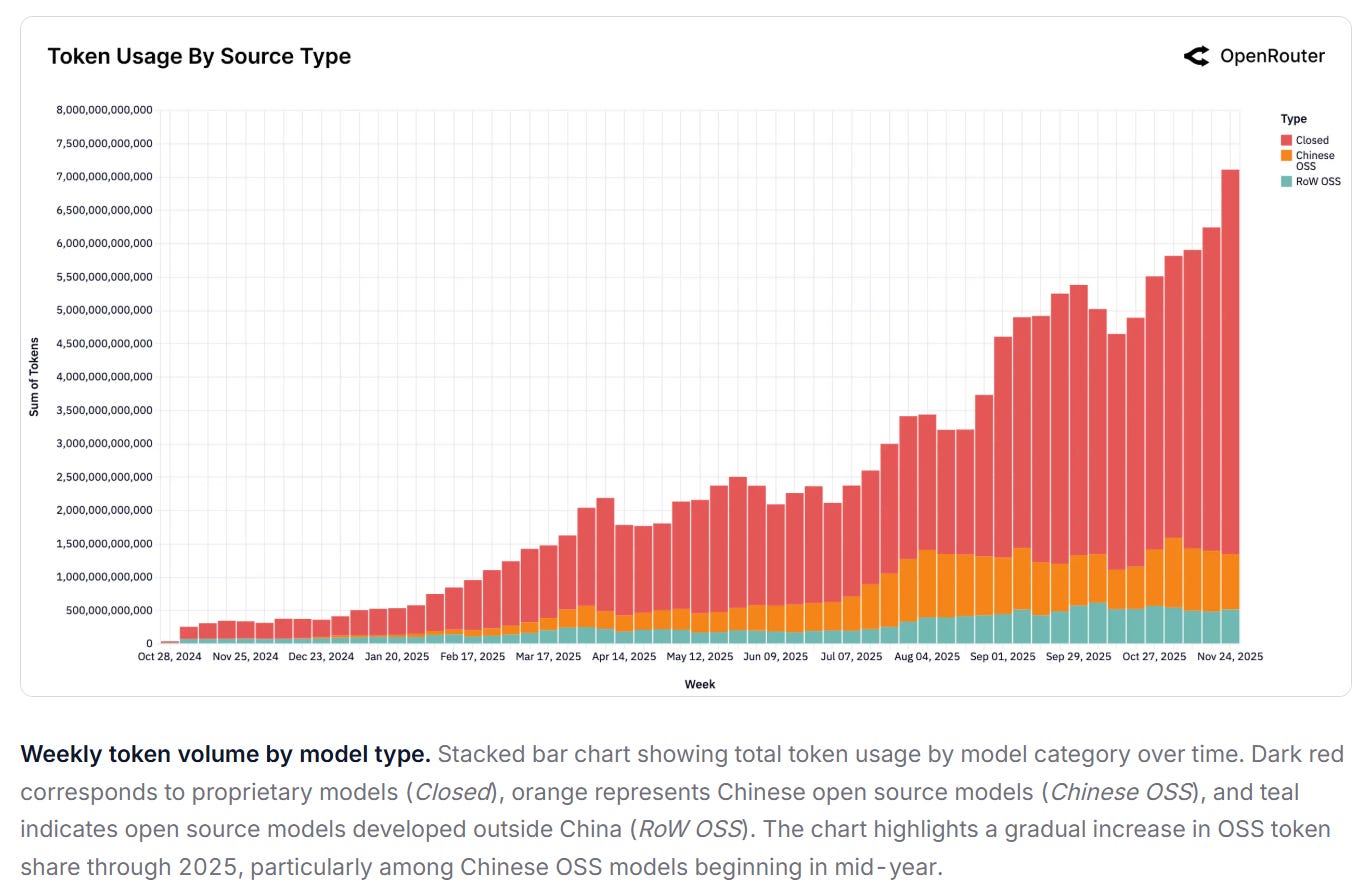
The real question, then, is not whether Chinese models are being used globally—they are. The question is: when the bulk of incremental usage happens outside China, does the profit pool follow the model, or does it follow billing and delivery?
“Open weights” do not automatically translate into API revenue share
Open weights, by themselves, typically do not create automatic API revenue share for the model author. Overseas usage of Chinese open models resembles a distribution network: the same weights can be hosted in different places, resold through different layers, or deployed by the user. What developers ultimately pay for is often not “the weights,” but a stable, usable inference endpoint. That is why the model’s country of origin and the place where inference is billed can separate so easily.
For overseas developers, the most common ways to “call Chinese open models via an API” can be grouped into five paths:
Aggregator routing layer → Inference platforms (MaaS / neo-cloud) → Hyperscaler model shelves → Self-hosting (HF / private deployment) → Direct API from Chinese vendors
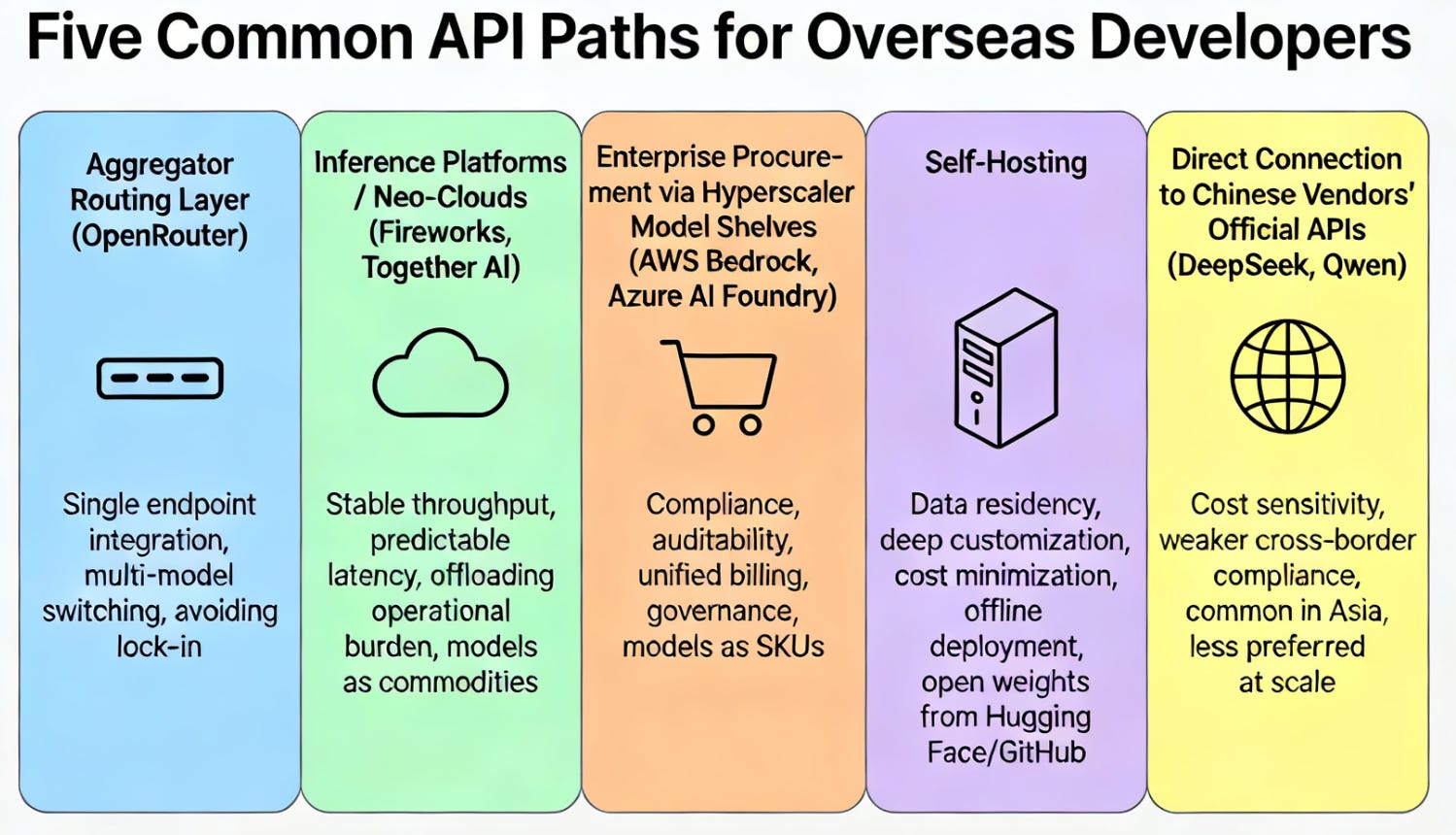
Five common API paths for overseas developers—and why they matter
The most common starting point is the aggregator routing layer. Many developers and tool vendors—especially IDEs, agent tools, and workflow platforms—do not want to integrate a separate SDK, authentication flow, and billing system for every model and every provider. The easier approach is to integrate a single OpenAI-compatible endpoint and select the target model by name in the request. OpenRouter’s value proposition is exactly this: it turns model selection into a string, hides delivery complexity behind the interface, and routes requests to different providers. The result is engineering flexibility—easy multi-model switching and fallback—rather than lock-in to a single model or a single cloud.
Downstream from routing layers are inference platforms / neo-clouds (MaaS). Platforms such as Fireworks or Together AI serve a different user profile: teams that care less about “whether it works” and more about stable throughput, predictable latency, transparent pricing, optimized inference stacks (vLLM, kernel/operator optimizations, caching strategies), and—critically—offloading operational burden. These teams buy inference endpoints from MaaS providers and treat models as interchangeable commodities. In practice, this means that even if the weights originate in China, the commercial relationship and billing often land first with the MaaS layer—and that MaaS layer, in order to scale delivery, tends to push underlying compute procurement and infrastructure consumption toward larger clouds and GPU suppliers.
A third path is enterprise procurement through hyperscaler model shelves. For enterprise buyers, the hardest part of model selection is rarely benchmark scores. It is compliance, auditability, access control, liability boundaries, and unified billing. Many enterprises do not want to integrate “a third-party API from another jurisdiction” directly. Instead, they prefer purchasing managed inference endpoints through AWS, Azure, or GCP—such as AWS Bedrock, Azure AI Foundry serverless endpoints, or GCP Vertex AI Model Garden managed APIs. The key point is that hyperscalers turn models into enterprise-purchasable SKUs: one API surface, one governance layer, one billing system, one security boundary. That is usually easier to approve internally than a bespoke integration where the enterprise must own the audit trail and responsibility boundary end-to-end.
Some users bypass intermediaries and self-host. This path is common when data residency is non-negotiable, deep customization is required, unit costs must be minimized, or offline/edge deployment is needed. Teams pull open weights from Hugging Face or GitHub and run inference on their own GPUs using stacks such as vLLM or TGI, or adopt “semi-managed” hosting through endpoint products. This route disperses inference workload across regional clouds, sovereign clouds, or private clusters. But from an industry perspective, if inference demand is happening overseas, it will still land somewhere in compute and infrastructure—just not necessarily concentrated in a small number of platforms.
Finally, a minority of users connect directly to Chinese vendors’ official APIs, such as DeepSeek or Qwen. This path is more common when teams are extremely cost-sensitive, cross-border compliance constraints are weaker, or the business footprint is already in Asia or near China. Media coverage of DeepSeek using off-peak pricing to attract API usage suggests that direct-vendor API demand does exist. Yet at scale, overseas developers tend to prefer routing layers, MaaS platforms, and hyperscaler shelves because they align better with real-world engineering and compliance constraints: easier integration, more stable delivery, and clearer responsibility boundaries.
What this implies for Chinese model vendors: “being used overseas” is not the same as “earning overseas API revenue”
For Chinese LLM vendors, the fact that overseas developers are using Chinese open models does not automatically mean the vendors are earning overseas API dollars. Sustained, measurable revenue share is more likely only when the vendor controls the charging point—through direct APIs, by acting as a provider in routing ecosystems, or by being the seller of record on hyperscaler shelves. Otherwise, a larger share of the economics is likely to remain with overseas inference platforms and hyperscalers at the hosting, billing, and delivery layers.
In the inference era, tokens behave like electricity: electricity can be “generated” anywhere (model capability), but where the meter sits (billing and hosting) and who operates the grid (delivery platforms and infrastructure) typically determine who earns the most consistently. That brings the question back in a sharper form: through which delivery paths are these “overseas Chinese-model tokens” actually flowing, and whose revenue line are they most likely to strengthen?
Why “Chinese-model tokens outside China” are increasingly an increment for U.S. cloud hyperscalers
According to OpenRouter, starting from a negligible base in late 2024 (weekly share as low as 1.2%), Chinese OSS models steadily gained traction, reaching nearly 30% of total usage among all models in some weeks. Over the one-year window, they averaged approximately 13.0% of weekly token volume, with strong growth concentrated in the second half of 2025. For comparison, RoW OSS models averaged 13.7%, while proprietary RoW models retained the largest share (70% on average). The expansion of Chinese OSS reflects not only competitive quality, but also rapid iteration and dense release cycles. Models like Qwen and DeepSeek maintained regular model releases that enabled fast adaptation to emerging workloads. This pattern has materially reshaped the open source segment and progressed global competition across the LLM landscape.
If mainland China accounts for only ~5–6% of total token volume, yet Chinese models are already processing trillion-scale weekly throughput on OpenRouter’s leaderboard and account for ~20% token share, then the natural question is: where does the remaining block of “Chinese-model tokens outside China” actually run—and where is it billed?
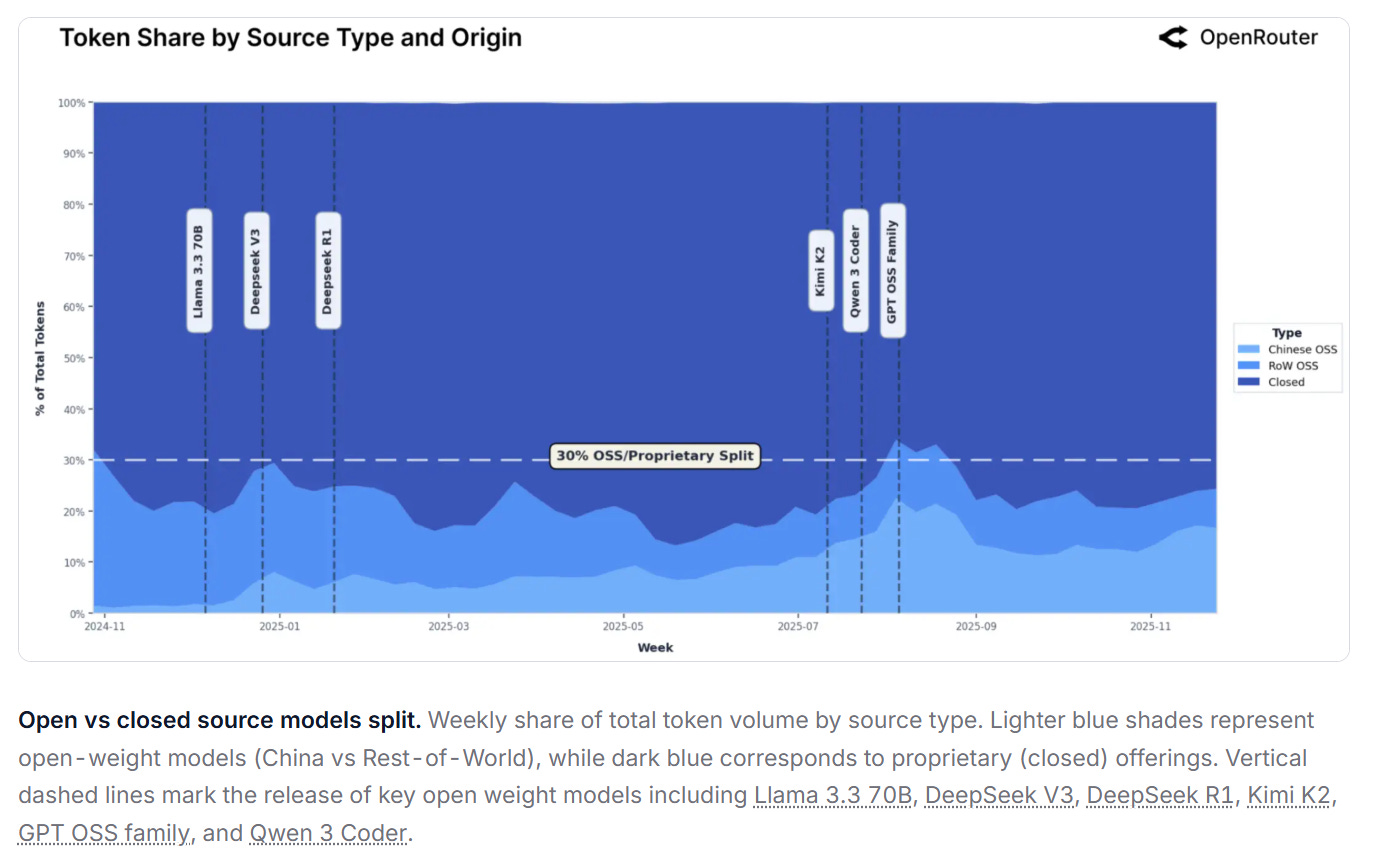
For overseas developers and enterprises, the path of least friction—and the easiest to clear security and audit reviews—is usually not to integrate “an API from China” directly. Instead, the default path is to consume Chinese models inside a U.S. hyperscaler’s managed framework, treating them as standard SKUs. The model supply may originate in China, but inference hosting and billing tend to settle more naturally inside cloud platforms such as AWS and Azure.
Hyperscalers have effectively productized Chinese models as cloud-native managed services, packaging the most sensitive enterprise requirements into a single, standardized answer: one API surface, one SLA, one security and governance layer, and one bill.
AWS offers the cleanest illustration. AWS publicly announced that DeepSeek-R1 is available in Amazon Bedrock as a fully managed, serverless model, and explicitly listed the supported regions—US East (N. Virginia), US East (Ohio), and US West (Oregon)—with delivery via cross-Region inference. In practical terms, this means that even if the user sits outside the United States, once the customer chooses the Bedrock path, the inference workload is hosted in those AWS regions and the spending is captured within the AWS billing system.
Azure follows the same logic. Microsoft’s official Azure blog states that DeepSeek R1 is available in the Azure AI Foundry model catalog and can be invoked “via a serverless endpoint,” positioned within a “trusted, scalable, enterprise-ready platform” that meets SLA, security, and responsible-AI commitments. For enterprises that care about data, compliance, auditability, and vendor accountability, a managed endpoint inside Azure is typically more procureable—and more controllable—than wiring up a third-party API directly. As a result, the same pool of “Chinese-model tokens outside China” is more likely to become Azure inference load and Azure revenue.
This is why, for token growth occurring within North America, Europe, Singapore, and other overseas billing systems, U.S. hyperscalers are not “replacing” Chinese models. They are providing the delivery wrapper that makes Chinese models usable at scale inside enterprise environments. Models can be swapped; meters and delivery systems are harder to swap.
That raises the next question: as hyperscalers continue to list Chinese models as managed SKUs, how exactly do they monetize this growth? Does the benefit stop at “model invocation fees,” or does it spill over into a much larger infrastructure profit pool?
What this means for AWS, GCP, and Azure: it looks like “pick-and-shovel” economics—but the form factor is changing
In this structure, the upside for AWS, GCP, and Azure increasingly resembles pick-and-shovel economics. They do not need to win every model benchmark or “model-versus-model” matchup. They just need to keep incremental inference workloads on their clouds, converting token growth into GPU hours, network egress and cross-region traffic, storage, and governance-layer consumption.
Hyperscalers are turning “open weights” into standardized managed products—and pulling in overseas inference load
The first shift is straightforward: hyperscalers are productizing open-weight models as fully managed SKUs, which directly absorbs inference demand that would otherwise be scattered across self-hosting and third-party platforms.
AWS Bedrock is a clear example. By late 2025, Bedrock added 18 fully managed open-weight models, explicitly including suppliers such as MiniMax, Moonshot (Kimi), and Qwen. In February 2026, it continued to list a new wave of frontier open-weight models—DeepSeek V3.2, MiniMax M2.1, GLM 4.7, Kimi K2.5, and Qwen3 Coder, among others. For an overseas enterprise, this effectively turns “using Chinese models” into a shorter, more auditable path: no self-hosting, no bespoke integrations, and no need to personally own the operational and security boundary.
A similar “shelf strategy” is visible in Google Cloud. Vertex AI Model Garden offers managed API access to models like DeepSeek R1, and positions managed open models as part of its MaaS (model-as-a-service) workflow. The documentation describes these offerings as serverless managed APIs, explicitly emphasizing that users do not need to build or operate inference infrastructure themselves. The Qwen family also appears in the managed catalog as callable open-weight models. For hyperscalers, this reframes competition away from “whose model is best” and toward whose platform can onboard, host, and reliably deliver the models that developers and enterprises actually want—fast. The faster a cloud can turn a hot model into a managed SKU with production-grade delivery, the more likely it is to capture the inference pipeline as those models “export” into global usage.
Azure’s strategy leans even more heavily into enterprise procurement and unified governance. The positioning of Foundry Models and the DeepSeek-R1 listing emphasizes unified billing, governance, a single license, and enterprise-grade infrastructure—a complete procurement-ready package. For many global companies, the real gate is not “can the model run,” but “can it be bought, governed, and audited inside existing IT and compliance frameworks.” Once Chinese models become purchasable, governable, and portable cloud-native products inside Foundry, the billing and operational center of gravity naturally shifts toward Azure.
The benefit is not just “model invocation revenue”—it expands into the broader delivery stack
The second shift is where the pick-and-shovel analogy becomes financially meaningful. Once inference workloads sit on cloud, token growth does not translate into a single line item. It fans out into a wider stack of attach rates: GPU inference and autoscaling, cross-region traffic, logging and observability, caching and storage, IAM and key management, and content safety and compliance controls.
This matters even more given what OpenRouter’s “Top Apps” list signals about demand composition. The highest-throughput applications—OpenClaw, Kilo Code, liteLLM, Cline, and similar tooling—are overwhelmingly built for global developers and agentic workflows. High concurrency, long context windows, and multi-turn tool calls are normal for these products. That profile is precisely what turns token growth into persistent infrastructure consumption, not just sporadic API calls.
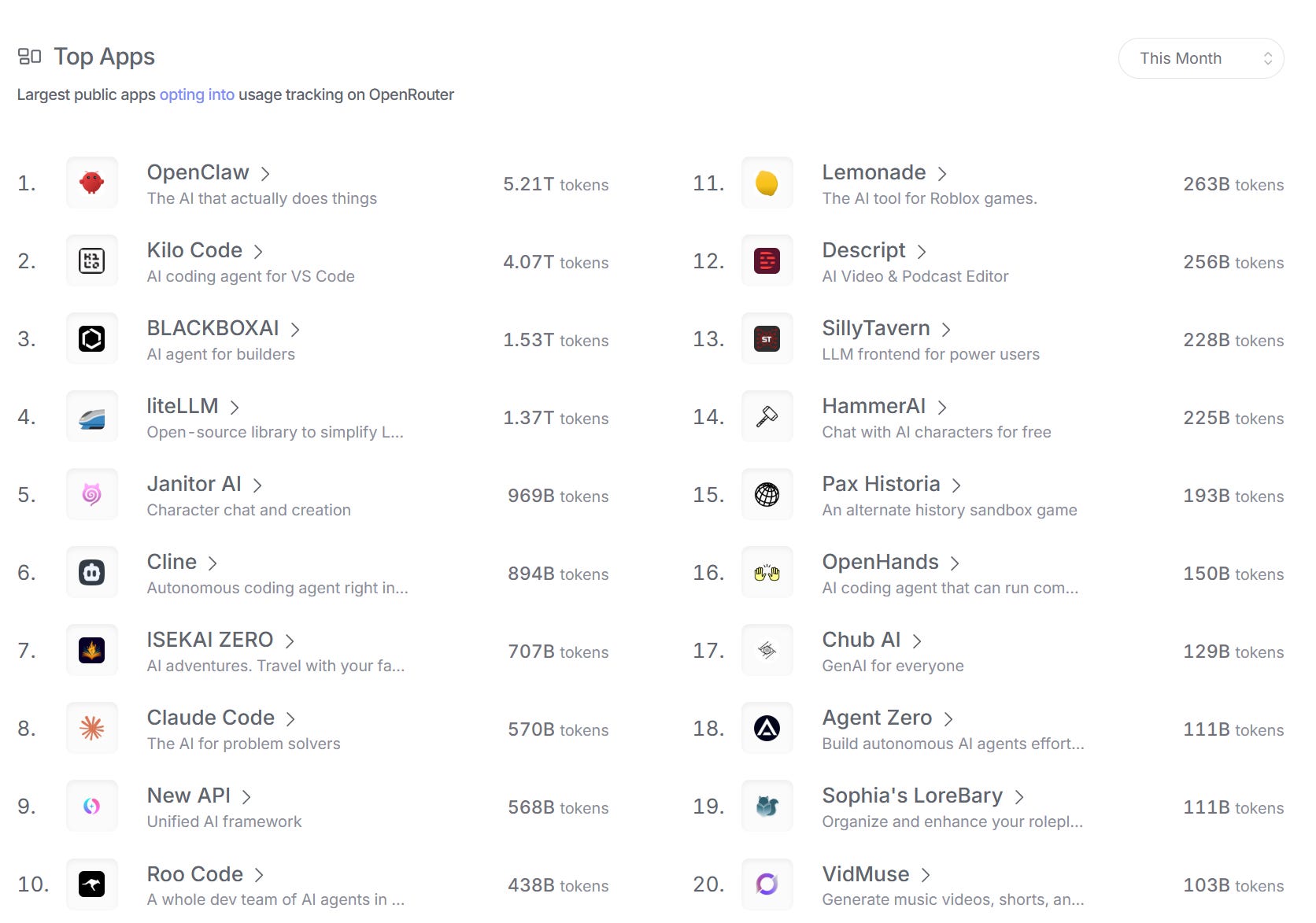
Pick-and-shovel economics are more durable, but the delivery form factor is evolving
The third shift is strategic. In the training-heavy phase, hyperscalers could lean on narratives like “giant training clusters” and “exclusive model partnerships.” In the inference-heavy phase, the story looks more like throughput plus a model supermarket. Model differentiation still matters, but customers increasingly treat models as swappable components, while reserving what is truly sticky for the platform layer: one API surface, one permissions model, one billing system, one observability stack, one compliance framework. Once switching costs move from “switching models” to “switching platforms,” hyperscalers capture not only a model’s usage, but an entire inference lifecycle and its attach-rate ecosystem.
That evolution also introduces two pressures. The first is pricing: open-weight models that are “good enough and cheaper” will keep pushing down average inference pricing, forcing hyperscalers to compete more on efficiency and scale. The second pressure comes from upstream in the value chain: routing and aggregation layers (OpenRouter and downstream agent tools) are absorbing some of the choice power and pricing leverage. Hyperscalers will need faster onboarding, stronger managed experiences, and deeper enterprise governance to pull that gravity back toward the platform.
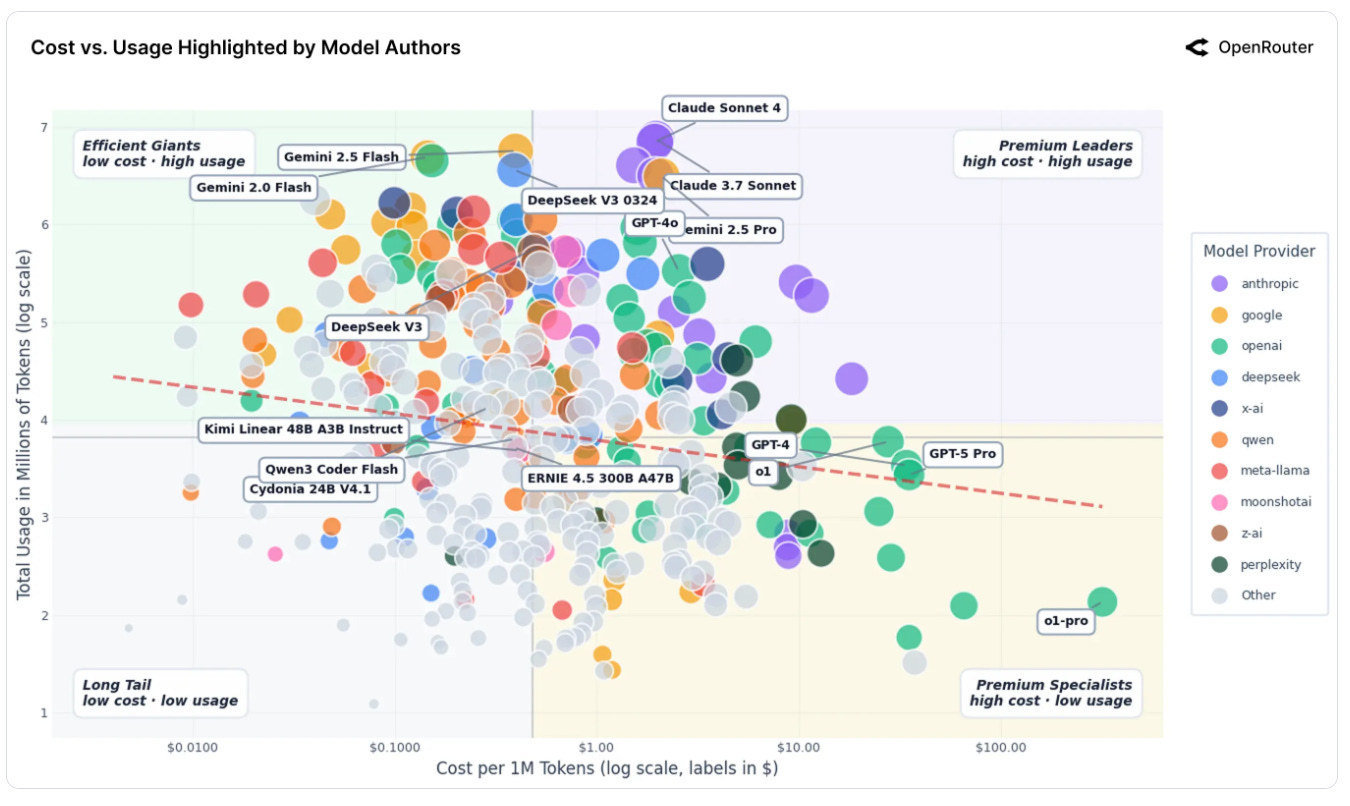
Conclusion and Outlook: U.S.–China LLM competition will intensify, but the profit pool first accrues to hosting and delivery
Chinese models are clearly scaling in an “export-style” pattern, and their global share is rising quickly. Yet on the demand side, mainland China still contributes only ~5–6% of total tokens. The bulk of incremental usage is being settled outside China, and it is amplified through cross-border billing hubs such as Singapore.
That shift moves the center of gravity in “U.S.–China AI competition” away from training headlines and leaderboard optics and toward a more grounded battleground: inference delivery and platform distribution. For AWS, GCP, and Azure, the globalization of Chinese models is not a threat in itself—it is a source of workload. As long as Chinese open models remain good enough and cheaper, they will be adopted at scale by overseas developers and toolchains. Hyperscalers, in turn, capture that growth by listing these models as managed SKUs—serverless endpoints, unified governance, and unified billing—and pulling incremental inference into their compute pools.
Three trends are likely to reinforce this dynamic. First, as “Top Apps” token composition continues to tilt toward coding agents and multi-step workflows, inference becomes denser—longer contexts, higher concurrency, more tool calls—driving a disproportionate increase in cloud attach rates across the delivery stack. Second, over the next six months, the pace and geographic coverage of hyperscaler “managed shelves” for Chinese models are likely to keep expanding, reducing friction for enterprise procurement and accelerating adoption. Third, continued cost compression in open models will keep pushing average unit pricing lower, shifting hyperscaler competition further away from “selling models” and toward selling delivery, governance, and scale efficiency.
The bottom line is straightforward. China’s rising global model share will keep sharpening the competitive narrative, but in the near term the profit pool is more likely to settle first in the hosting and delivery layer. In the inference era, where the meter runs often matters more than who shouts loudest.
Data Source:
1、State of AI
An Empirical 100 Trillion Token Study with OpenRouter
https://openrouter.ai/state-of-ai?utm_source=chatgpt.com
2、AI Model Rankings
https://openrouter.ai/rankings