
Do Not Underestimate Jensen Huang’s Judgment
Huawei is not just stacking chips. China’s AI compute strategy is shifting from chip-for-chip parity to system-level organization.

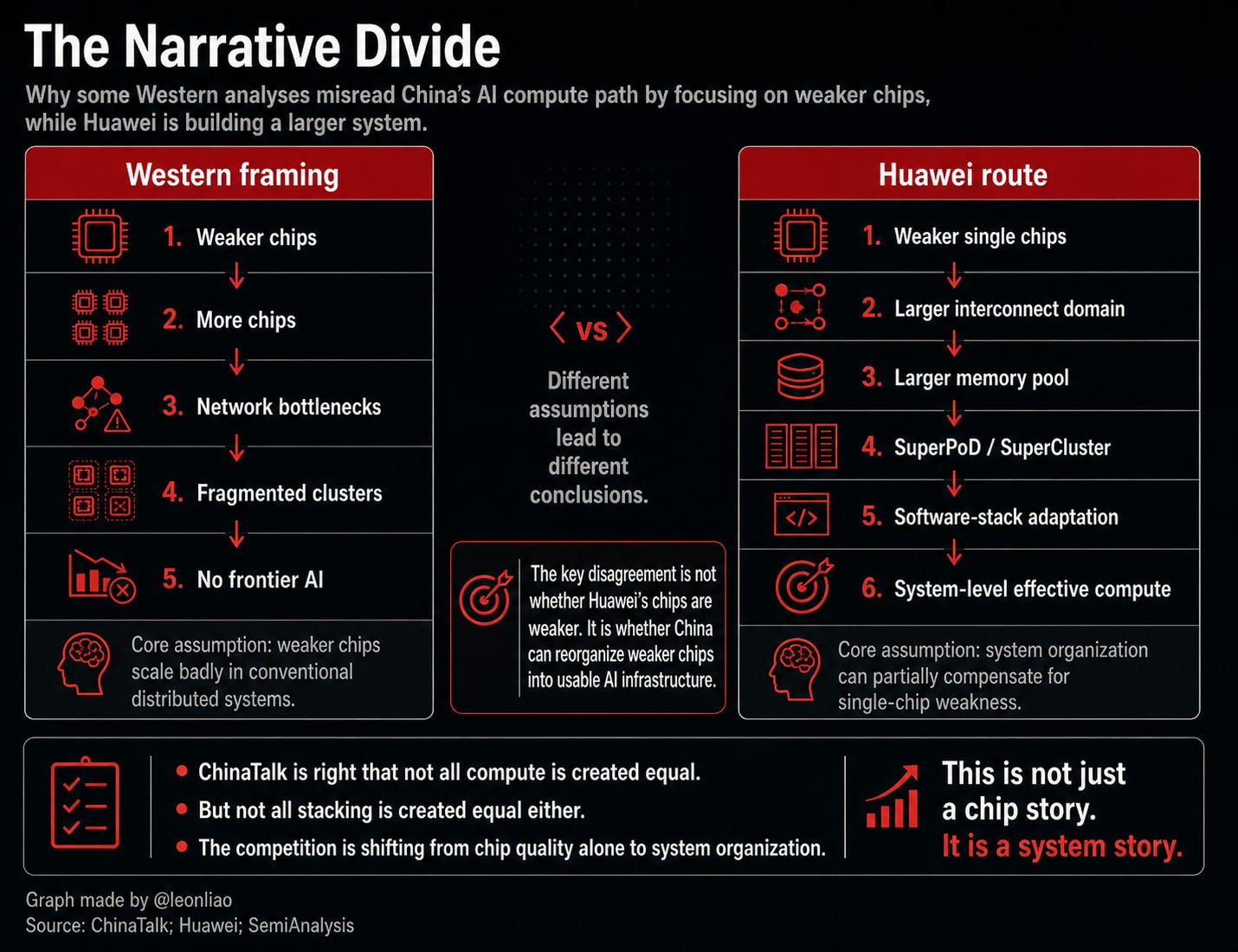
Why do some Western narratives misread China’s AI compute strategy by focusing too much on chips and too little on systems?And whether China can use UnifiedBus, all-optical interconnects, SuperPoDs, and SuperClusters to turn chips available under domestic process constraints into trainable, inference-capable, and operationally manageable system-level effective compute?
This essay is part of China AI System Series.
Executive Summary
Huawei’s AI compute strategy should be evaluated at the system level, not only at the single-chip level. Jensen Huang’s warning matters because China may not need every Ascend chip to match Nvidia chip-for-chip if it can organize available chips through larger interconnect domains, larger memory pools, optical networking, software adaptation, and data-center-scale system engineering.
ChinaTalk is right that “not all compute is created equal,” but its framework risks misreading Huawei’s path as crude chip stacking. The central issue is not whether mature-node chips or weak accelerators can be randomly connected to train frontier models. The more important question is whether Huawei can turn weaker single chips into system-level effective compute through UnifiedBus, SuperPoDs, SuperClusters, CANN, and cloud-level software adaptation.
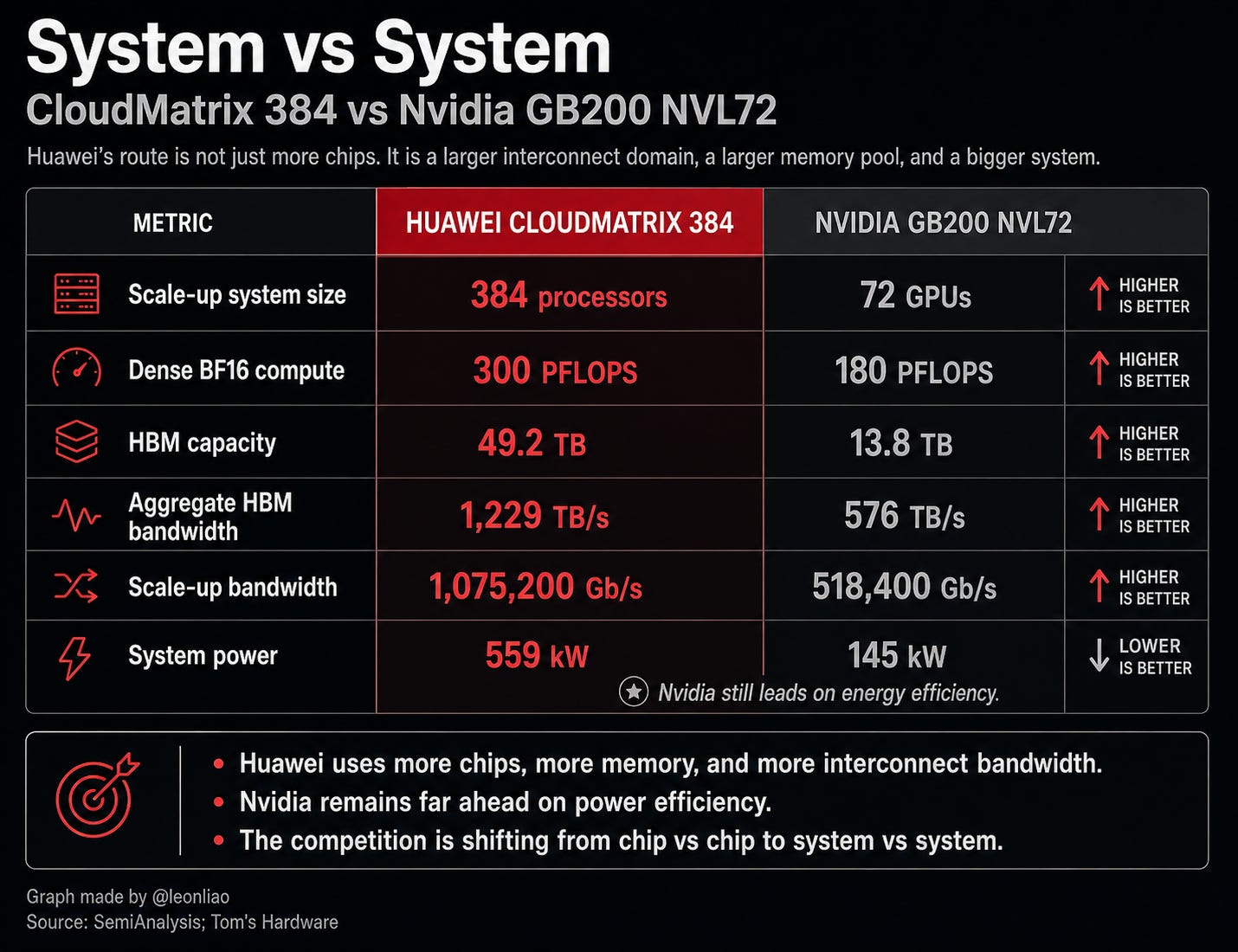
CloudMatrix 384 is the clearest counterexample to the “weaker chips plus more quantity” narrative. It uses 384 Ascend 910C processors versus 72 GPUs in Nvidia’s GB200 NVL72, delivering roughly 300 PFLOPS dense BF16 compute, 49.2 TB HBM capacity, 1,229 TB/s aggregate HBM bandwidth, and 1,075,200 Gb/s scale-up bandwidth. The trade-off is real: Huawei uses far more power, about 559 kW versus 145 kW for GB200 NVL72, but it demonstrates a viable system-level compensation strategy.
UnifiedBus and all-optical interconnects are central to Huawei’s AI compute strategy. The key variable is not simply chip count. It is whether Huawei can reduce distributed-training losses by expanding the scale-up domain, pooling memory, lowering communication overhead, and organizing many NPUs into a more coherent logical computing unit. This makes interconnect architecture a strategic variable, not a supporting detail.
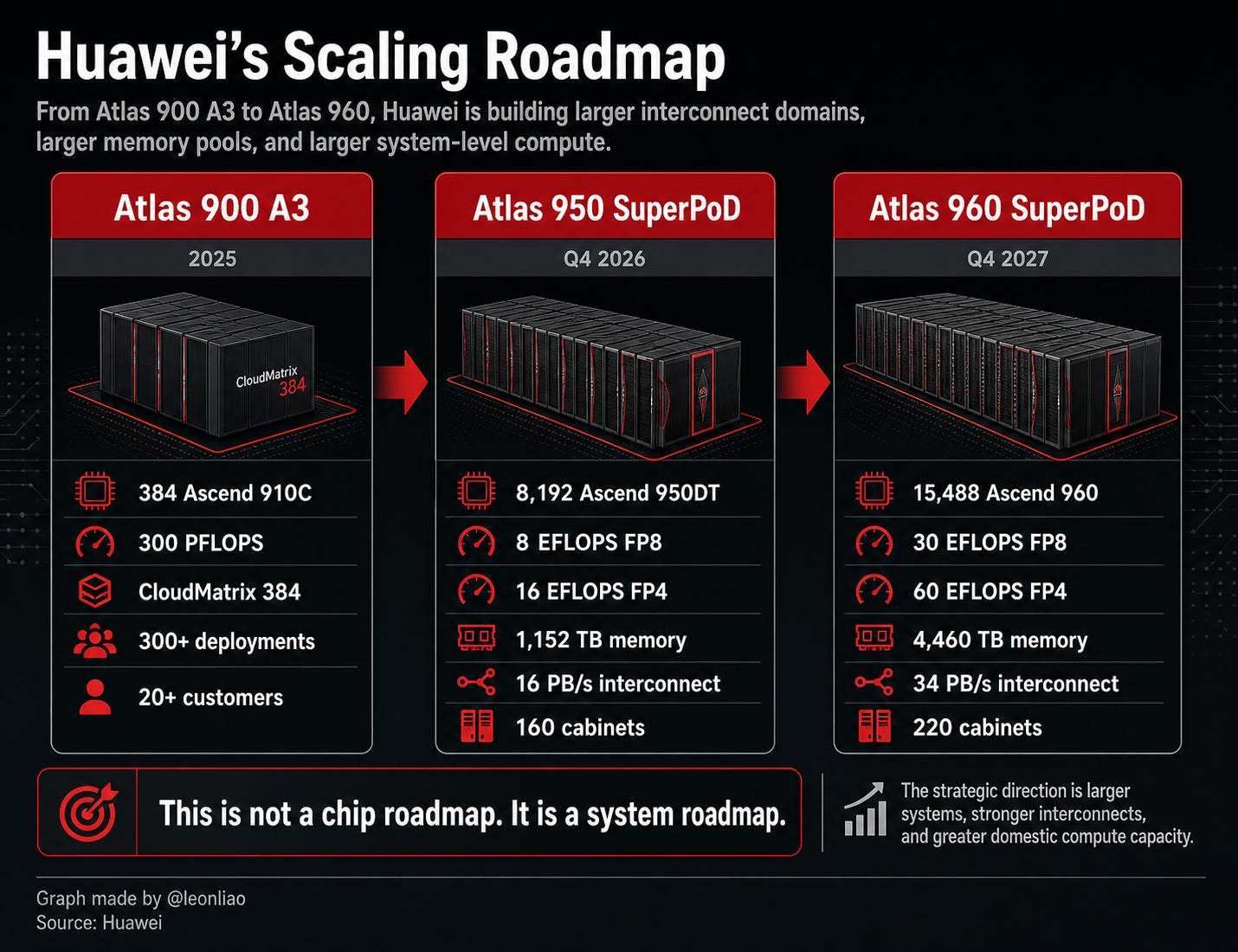
Atlas 950 SuperPoD shows that Huawei is building a roadmap of larger AI compute systems. With planned support for 8,192 Ascend 950DT chips, 8 EFLOPS FP8, 16 EFLOPS FP4, 16 PB/s interconnect bandwidth, and 1,152 TB total memory, Atlas 950 represents a broader attempt to build a Chinese version of the AI factory under constrained semiconductor conditions.
Huawei’s newly proposed Tau Scaling Law reinforces the same strategic logic inside the chip. Tau Scaling Law reframes semiconductor constraints around architecture, latency, logic folding, and system coordination, while UnifiedBus and SuperPoD address organization between chips. Together, they point to the same broader direction: when frontier process scaling is constrained, Huawei is trying to recover performance gains through system organization.

Do not underestimate Jensen Huang’s judgment as a great entrepreneur.
When Jensen Huang says that China may be able to connect four times, ten times, or even more chips to compensate for its restricted access to advanced chips, he is certainly not unaware of the importance of GPUs, HBM, low-precision computing, NVLink, InfiniBand, CUDA, and the software ecosystem. Quite the opposite. Few people in the world understand better than he does that Nvidia’s moat today is not a single GPU, but an AI infrastructure system built from GPUs, networking, memory, software libraries, developer ecosystems, cloud providers, data-center architecture, and model-training experience.
Precisely for that reason, Jensen’s comment deserves to be taken seriously. What he may really be pointing to is not that “all chips are the same,” but a deeper question: when a country cannot reliably access the most advanced GPUs, can it use larger-scale interconnects, larger memory pools, more intensive data-center construction, more complex software adaptation, and stronger system-level organization to reorganize weaker single chips into trainable, inference-capable, and operationally manageable system-level effective compute?
This is where many current Western analyses may be getting the story wrong.
ChinaTalk recently published an article “No Jensen, Not All Compute Is Created Equal”. That judgment is largely correct. Mature-node chips, automotive control chips, industrial MCUs, and home-appliance controllers cannot simply be treated as AI accelerators for training frontier large models. FLOPs are not the only metric. HBM bandwidth, numerical precision, interconnect bandwidth, communication latency, cluster concentration, and software ecosystems all matter. Large-model training is not an engineering problem that can be solved by randomly stacking any chips together. Frontier model training requires high-bandwidth memory, low-latency communication, mature distributed-training frameworks, stable hardware-software coordination, and system reliability that can survive long training runs without crashing.
There is nothing wrong with these technical observations.
The real problem is that ChinaTalk goes further and describes China’s AI compute path as a combination of “weaker chips + more quantity + traditional networks + fragmented clusters.” It constructs a hypothetical “Huaweiopolis” and argues that even if China can assemble equivalent FLOPs on paper, it still cannot train the next generation of frontier models because its chips are weaker, its interconnects are inferior, its networks are bottlenecked, its compute is fragmented, and its software is less mature. This framework appears technically sophisticated, but it may miss the most important point about Huawei’s actual path: Huawei today is not pursuing an ordinary scale-out strategy of simply stacking accelerator cards. It is pursuing system-level reorganization.
Huawei is certainly not claiming that a single Ascend 910C can beat a single B200. That claim would not hold. Nvidia still clearly leads in single-chip performance, energy efficiency, the CUDA ecosystem, the HBM supply chain, and the developer base. The point is that the key variable in China’s AI compute competition can no longer be measured only by whether one chip can match Nvidia chip-for-chip. The real variable has become whether China can use UnifiedBus, all-optical interconnects, SuperPoDs, SuperClusters, the CANN software stack, and its vast domestic application demand to organize chips available under its current process constraints into sufficiently usable AI infrastructure.
In other words, some Western analyses are not entirely wrong at the physical layer. They are wrong in their unit of analysis. They keep the competition fixed at “chip vs chip,” while Huawei is pushing the competition toward “system vs system.”
Huawei’s newly proposed Tau Scaling Law can also be understood within the same framework. At IEEE ISCAS 2026, Huawei proposed using “time scaling” to move beyond pure “geometric scaling,” compressing signal propagation delay through technologies such as logic folding to improve transistor density and system performance. This does not mean Huawei has already solved all advanced-process constraints. But it does show that Huawei is trying to reframe semiconductor constraints as problems of architecture, latency, interconnect, and system-level coordination. Tau Scaling Law operates inside the chip. UnifiedBus and SuperPoD operate between chips. Both point in the same direction: when single-point process scaling is constrained, Huawei is trying to recover performance gains through system organization.

1. ChinaTalk Is Right About Compute Quality, but It Underestimates System Organization
“Not all compute is created equal” is a correct statement. But it has another half: not all forms of “stacking chips” are created equal either.
If a large number of low-end chips are crudely connected through a traditional network, they obviously cannot train a GPT-4-class large model. Network communication will drag down efficiency. HBM capacity and bandwidth will constrain model partitioning. Long training runs will encounter problems of failure recovery, gradient synchronization, and declining utilization. This kind of stacking may produce impressive paper FLOPs, but it is difficult to convert into real effective training capability.
But that is not what Huawei is doing.
Huawei’s route is closer to this: single-chip performance is insufficient, so it compensates through SuperPoD interconnects; process technology is constrained, so it compensates through a larger interconnect domain and a larger memory pool; CUDA cannot be replicated, so it reduces migration costs through CANN, MindSpore, PyTorch adaptation, and the ModelArts cloud platform; peak energy efficiency cannot be matched in the short term, so it trades more electricity, larger data centers, and domestic supply-chain security for deployability.
This is a more expensive, more power-hungry, and more engineering-intensive path. But it is not illogical. Its core is not to deny that Nvidia has stronger single chips. Its core is to acknowledge the gap and then convert that gap into a systems-engineering problem.
Many Chinese industrial catch-up stories did not begin with the strongest single-point technology. They began with system organization. China did not initially have the world’s strongest single solar cell, the strongest automotive chip, the strongest industrial software product, or the strongest individual high-speed rail component. But China has often been able to use supply-chain organization, engineering iteration, infrastructure construction, market scale, policy coordination, and application diffusion to push a technological system rapidly toward large-scale deployment. AI compute may be entering a similar phase.
This does not mean Huawei has already caught up with Nvidia. The more accurate statement is that Huawei is trying to convert Nvidia’s “single-chip advantage” into a “system-organization problem” that China knows how to handle.
2. CloudMatrix 384 Is the Most Direct Counterexample
If we only compare Ascend 910C with B200, the conclusion is simple: Huawei is behind.
But if we compare CloudMatrix 384 with GB200 NVL72, the conclusion becomes much more complicated.
CloudMatrix 384 uses 384 Ascend 910C chips, while Nvidia’s GB200 NVL72 uses 72 GPUs. This comparison itself reveals the difference between the two paths. Nvidia relies on stronger single chips, higher energy efficiency, and a more mature software ecosystem to deliver extremely high compute density at a smaller scale. Huawei uses more chips, a larger interconnect, a larger memory pool, and higher power consumption to organize weaker single chips into a larger system.
CloudMatrix 384 delivers about 300 PFLOPS of dense BF16 compute, compared with about 180 PFLOPS for GB200 NVL72.
CloudMatrix 384 has about 49.2 TB of HBM capacity, compared with about 13.8 TB for GB200 NVL72.
CloudMatrix 384 has about 1,229 TB/s of aggregate HBM bandwidth, compared with about 576 TB/s for GB200 NVL72.
CloudMatrix 384 has about 1,075,200 Gb/s of scale-up bandwidth, compared with about 518,400 Gb/s for GB200 NVL72.
CloudMatrix 384 has a scale-up domain size of 384 processors, compared with 72 GPUs in GB200 NVL72.
These numbers should not be simplistically interpreted as “Huawei has surpassed Nvidia.” The cost of CloudMatrix 384 is also very clear: its system power consumption is about 559 kW, compared with about 145 kW for GB200 NVL72. Nvidia still clearly leads in performance per watt. In other words, Huawei is using more silicon, more electricity, more optical interconnects, more cabinet space, and more complex engineering to obtain system-level compute metrics that approach or partially exceed Nvidia’s system-level metrics.
But this is exactly where the ChinaTalk framework becomes problematic. It sees China’s path as “weaker chip stacking,” while CloudMatrix 384 shows something else: Huawei is trying to turn “stacking” into a system architecture.
This is not a minor difference. Ordinary chip stacking means linearly increasing the number of devices. System architecture means redefining how chips communicate, how memory is organized, how tasks are scheduled, how failures are recovered from, how models are partitioned, and how software is adapted. The former is just quantity expansion. The latter is engineering-system reconstruction.
The significance of CloudMatrix 384 is not that it proves Huawei has already surpassed Nvidia. Its significance is that it proves China is not locked into the path of “no access to the strongest GPUs, therefore no AI development.” It shows that under constrained conditions, China can choose a more power-hungry, heavier, more complex, but available path to keep pushing AI compute forward.
In a normal free-market environment, most customers would probably still choose Nvidia because it is more energy efficient, more mature, and easier to use. But under export controls, the question is no longer a comparison between the “best possible system” and another “best possible system.” It is a comparison between an available system and an unavailable system. For Chinese companies, a less efficient domestic system that can be purchased, deployed, maintained, expanded, and secured against supply-chain risk may be strategically more valuable than a theoretically more advanced foreign system whose availability is unstable.
3. The Real Variable Is the Interconnect Domain, Not the Number of Chips
The technical bottleneck ChinaTalk emphasizes most is network bandwidth. This issue is indeed important. Large-model training does not allow each card to compute in isolation. Model parameters, gradients, activations, and intermediate results must be constantly synchronized across devices. The more chips there are, the greater the communication pressure. The slower the network, the more compute is wasted. Higher theoretical FLOPs do not necessarily translate into higher real training throughput.
But the real question here is not whether network bottlenecks exist. The real question is whether those bottlenecks can be reduced through a new system architecture.
Huawei’s answer is UnifiedBus, also known as Lingqu interconnect. Its core objective is not to make external networks magically faster than HBM, nor to deny the existence of physical distance and communication latency. Its goal is to minimize the hierarchical losses of traditional distributed clusters across nodes, between nodes, between cabinets, and between machine rooms. Traditional GPU clusters are usually fast inside a node, then connected across nodes through InfiniBand or Ethernet, with additional communication overhead across cabinets and clusters. Huawei wants to use a unified protocol, peer-to-peer coordination, resource pooling, all-optical interconnects, and a larger scale-up domain to organize large numbers of NPUs as much as possible into one logical computing unit.
The key to this direction is not “network replacing HBM.” It is reducing system loss in distributed training.
In this sense, UnifiedBus is not a supporting technology. It is the core strategy of Huawei’s AI compute path. It is trying to answer the following questions: if China’s single-chip performance is one generation behind, can a larger interconnect domain organize more chips effectively? If more chips create more communication, can new interconnect protocols, optical links, and system scheduling reduce communication loss? If CUDA cannot be replicated, can hardware-software co-design and China’s domestic application scenarios gradually improve effective utilization?
This is why the next article needs to focus specifically on Huawei’s interconnect architecture. The real fulcrum of Huawei’s AI compute path is not the Ascend chip in isolation. It is how Ascend chips are organized.
4. Atlas 950 Shows Not a Product, but a Path
CloudMatrix 384 already shows Huawei’s system-compensation logic. Atlas 950 SuperPoD magnifies that logic further.
Atlas 950 SuperPoD is planned to support up to 8,192 Ascend 950DT chips, twenty times the scale of Atlas 900 A3.
A full configuration includes 160 cabinets, of which 128 are compute cabinets and 32 are communication cabinets, occupying about 1,000 square meters, all connected through all-optical interconnects.
Its target specifications are 8 EFLOPS FP8, 16 EFLOPS FP4, 16 PB/s interconnect bandwidth, and 1,152 TB of total memory.
It is planned for launch in the fourth quarter of 2026.
From the perspective of traditional GPU-cluster thinking, this scale naturally raises doubts: How can 8,192 chips maintain communication efficiency? How can utilization decline be avoided? How will failures be handled? How can long training runs remain stable? How will developers actually use it?
These doubts are reasonable.
But precisely because these questions exist, Atlas 950 is not an ordinary “large cluster.” It is Huawei’s attempt to define a new computing unit. It is not simply putting 8,192 chips together. It designs compute cabinets, communication cabinets, optical interconnects, unified protocols, memory organization, system scheduling, and the software stack as a single whole. Its goal is not to turn every Ascend chip into a B200. Its goal is to make 8,192 Ascend chips become a usable AI compute system across enough scenarios.
That is what “system-level effective compute” means.
AI compute competition is expanding from single-point performance to organizational capability. A strong single chip certainly matters. But as models grow larger, inference demand becomes more dispersed, industry applications multiply, and data centers become the new industrial infrastructure of the AI age, a country’s ability to organize large-scale compute systems will also become a core competitive capability.
Nvidia is also building systems. In fact, Nvidia is the world’s strongest AI systems company, not merely a GPU company. GB200, NVL72, NVLink, NVSwitch, InfiniBand, Spectrum-X, CUDA, TensorRT, NCCL, and various cloud reference architectures are all Nvidia’s way of organizing AI compute into an “AI factory.” What Huawei is doing today is trying to build a Chinese version of that AI factory, but under a more constrained semiconductor environment.
This route is heavier and more expensive. But it fits China’s reality under long-term technological restriction.
5. What Western Narratives Most Easily Miss: China’s “Second-Best Deployability”
Many Western analyses of China’s technological capabilities tend to frame the issue as a single-point comparison: whose chip is stronger, whose model is stronger, whose papers are more numerous, whose ecosystem is more open, whose companies have higher profit margins.
All of these comparisons matter. But they do not necessarily explain the resilience of the Chinese system.
China’s real advantage often does not lie in possessing the optimal technology from the beginning. It lies in the ability to deploy second-best technology into large-scale systems. This capability includes massive domestic demand, infrastructure-investment capacity, electricity and data-center construction, supply-chain coordination, participation by local governments and telecom operators, migration pressure from cloud providers and industry customers, and the domestic-substitution drive formed under external restrictions.
If a domestic AI compute system is only 50% as efficient as Nvidia’s system, it may be difficult to win at scale in a free market. But if Nvidia’s most advanced systems cannot be reliably obtained, if government and enterprise customers place greater value on supply-chain security, if local intelligent-computing centers need domestic solutions, and if operators, cloud providers, industrial customers, and government systems continuously create real demand, then even a 50%-efficient system has the soil for continuous iteration.
This is the most important mechanism of domestic substitution: it does not begin by being better. It begins by being usable, then improves through demand.
This is also what ChinaTalk-style analyses often underestimate. Starting from the technical optimum, they easily conclude that weaker chips cannot replace stronger chips. But China’s development path often does not start from the optimal solution. It starts from the deployable solution. Once a system can be deployed, demand enters. Once demand enters, engineers optimize. Once engineers optimize, the software ecosystem improves. Once the software ecosystem improves, effective utilization rises. Once effective utilization rises, the next generation of hardware has a clearer direction for iteration.
This is not a story about surpassing Nvidia in the short term. It is a story about the formation of a substitution ecosystem.
6. Export Controls Are Helping Huawei Obtain a Market
If Chinese companies could freely purchase H100, H200, B200, GB200, and future Rubin systems, many of them would of course continue to choose Nvidia. Nvidia is stronger, more energy efficient, more mature, easier to use, deeper in developer ecosystem, more compatible with model code, and richer in cloud-service and tuning experience.
But export controls change market choice.
When the best product cannot be reliably obtained, the second-best domestic product gains strategic value. It does not need to beat Nvidia under fully open market conditions. It only needs to be sufficiently usable, deployable, and improvable under restricted conditions to create its own market space.
The original intention of U.S. restrictions on advanced GPUs to China is to slow China’s frontier AI capabilities. But they are also creating a huge market forced to turn toward domestic compute. Companies that would not have migrated voluntarily now must evaluate Ascend. Engineering teams that did not want to adapt to CANN now must learn it. Cloud providers that only wanted to procure Nvidia now must build domestic compute pools. Domestic supply chains that previously had no opportunity to enter mainstream AI infrastructure suddenly obtain real customers, real problems, and real iteration opportunities.
This does not mean export controls are ineffective. They do increase the difficulty of training frontier models in China. They raise energy consumption and costs. They slow certain technical paths. But they are also pushing the formation of a parallel AI compute stack.
This stack may be less efficient, more closed, more dependent on the domestic market, more power-hungry, and less attractive to global developers. But it will be more controllable, more domestic, and more aligned with China’s security needs under long-term technological restriction.
This is the real meaning behind Jensen Huang’s warning.
7. Conclusion: Do Not Misread China’s Path as “Weaker Chip Stacking”
Huawei’s AI compute path should not be romanticized. It has very real weaknesses. Single-chip performance is behind. Energy efficiency is behind. The software ecosystem is weaker than CUDA. Frontier large-model training cases still need to be verified. The long-term stability and real utilization of large-scale SuperPoDs remain unproven. The Atlas 950 and Atlas 960 roadmaps are ambitious, but roadmaps are not actual training results. What needs to be observed in the future is whether these systems can train large models stably, reduce developer migration costs, support high-concurrency inference, and achieve sufficiently high utilization among real customers.
But Huawei’s path should also not be simplified as “stacking weaker chips in larger quantities.”
Huawei is using weaker single chips, larger interconnect domains, larger memory pools, all-optical interconnects, SuperPoDs, SuperClusters, domestic supply-chain control, and software-stack adaptation to build system-level AI compute.
Nvidia’s advantages are single-chip performance, CUDA, energy efficiency, and the global ecosystem. Huawei’s counterattack lies in SuperPoDs, optical interconnects, domestic supply chains, and system organization capability.
AI compute competition is moving from chip vs chip to system vs system.
If we look only at chips, China is still behind. If we look at systems, China’s path already deserves serious study. The misjudgment in some Western narratives is not that they overestimate Nvidia. It is that they underestimate China’s ability to reorganize constrained technologies into deployable systems.
That is the core argument of this first article: Huawei is not just stacking chips. It is turning the AI compute problem into a systems-engineering problem that China knows how to work on.
In the next article, I will write specifically about Huawei Ascend and its interconnect architecture, focusing on how UnifiedBus, all-optical interconnects, CloudMatrix, Atlas SuperPoD, and SuperCluster attempt to organize weaker single chips into system-level effective compute. Stay tuned.
This essay is part of China AI System Series. This series examines China’s AI development not as a narrow model race, but as a system-level competition involving chips, compute infrastructure, power systems, data centers, software ecosystems, industrial deployment, and state capacity. Future essays will continue to follow Huawei Ascend, UnifiedBus, CloudMatrix, Atlas SuperPoD, domestic AI chip substitution, AI electricity demand, low-cost inference, DeepSeek, and the broader formation of China’s second AI compute stack.
If you are interested in how AI is becoming a contest of industrial systems, infrastructure capacity, and global power, follow China as a System and subscribe for future essays in this series.
Huawei’s pivot to system-level orchestration is smart, but it’s not novel. The 2015 Tianhe-2A upgrade already fused homegrown Matrix-2000 accelerators with Intel bricks under a unified scheduler, same playbook Huang now says will beat CUDA.
great insight. AI compute is about parallel processing. there are different ways to skin the cat - more powerful chips or more chips connected better and with superior algorithms. it is never about one or the other. It is about pursuing both at the same time - i.e. a system approach. Huawei is pursuing a multi-pronged strategy to address both chip level competitiveness and system-level integration superiority. Given time, we'll see a new paradigm and new reality.