
China AI System #5: Low-Cost Open Models Are Squeezing Closed-Model Premiums—So What Happens to Claude and ChatGPT’s Pricing Power?
Open models aren’t “killing” Claude and ChatGPT—they’re steadily compressing the premium, which concentrates in enterprise trust, governance, and certainty pricing.

This is part of China AI System, a series on how China is turning AI from a model race into an industrial system—where compute, deployment, capital discipline, and market scale compound into industrial advantage. I track the mechanics of China’s AI buildout: inference economics and cost compression, the stack from chips to clouds to apps, the adoption flywheels across industries and consumer products, and the global pathways through which value—and the profit pool—are captured.
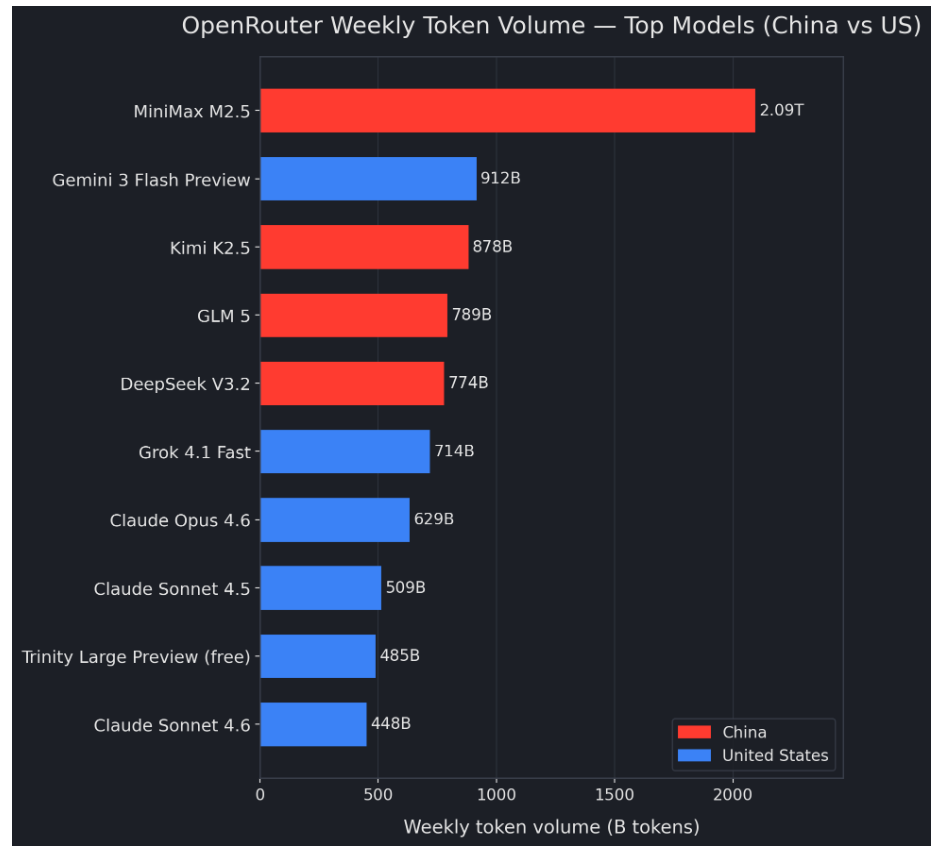
Lower costs, shorter waits, and expanding services are drawing more overseas Over the past week or two, the token share of Chinese open models has jumped sharply—reaching 30%+ in parts of the observable OpenRouter’s ecosystem. Four of the top five models by weekly token volume are Chinese. The only non-Chinese model in the top five is Google’s Gemini 3 Flash Preview. Expanding to the top ten, those four Chinese models together account for ~4.53T tokens, which is more than half of the top-10 total (~8.23T tokens).
Should this be read as an early sign that closed models like Claude and ChatGPT are about to be replaced? Or is the more immediate risk something subtler—erosion of pricing power, as “good enough” models pull a growing share of developer and SMB workloads into a lower-cost tier?
From model capability to economics: the performance–latency–reliability–cost tetrahedron
Closed models (Claude, GPT) have historically justified $15–$25 per 1M output tokens in the high-end tier because they delivered a bundle: stronger reasoning and code reliability, better instruction following, better tool use, and fewer catastrophic failures. That bundle is still real—but it is no longer uncontested. Anthropic’s own current list prices put Claude Opus 4.6 at $5 / $25 per 1M input/output tokens and Claude Sonnet 4.6 at $3 / $15. OpenAI’s flagship GPT-5.2 sits in a similar “expensive output” regime (e.g., $1.75 input / $14 output per 1M tokens, with discounted cached input).
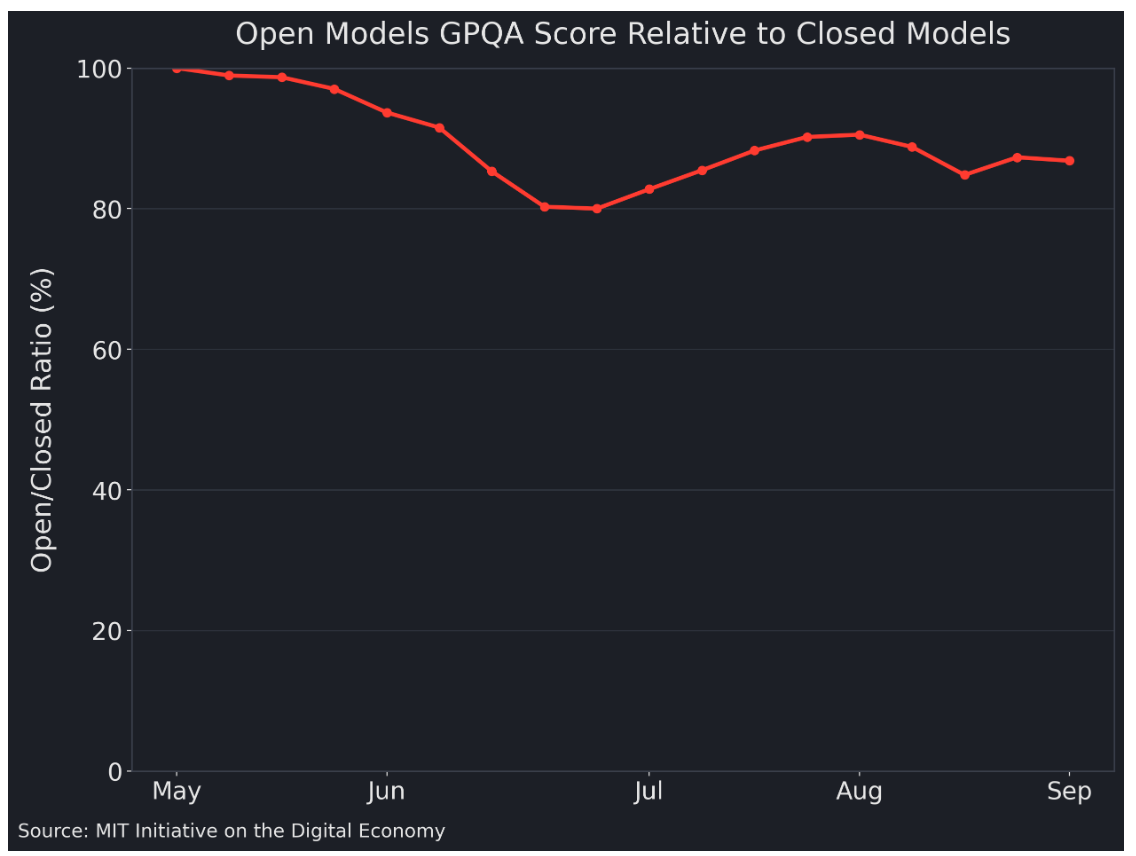
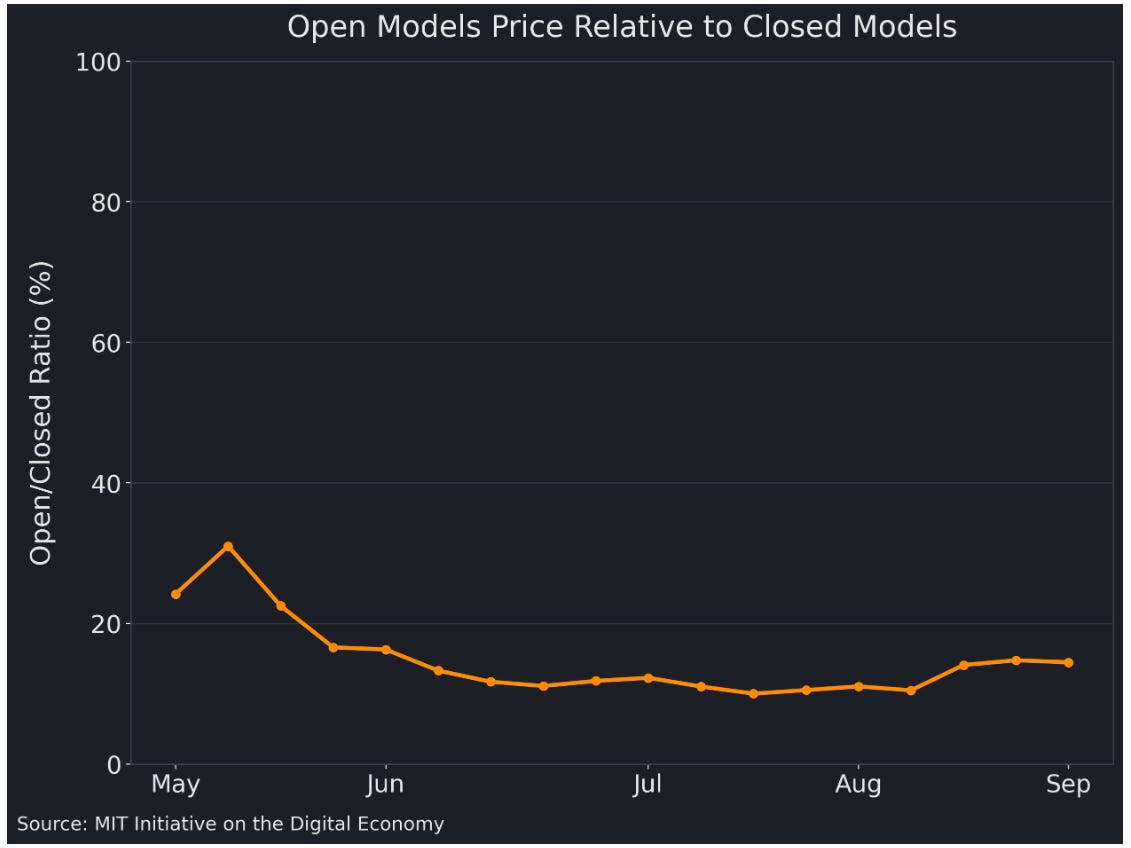
A recent MIT working paper uses OpenRouter—a routing layer that sits across models and providers—as a real-world laboratory for how the market actually prices and chooses models, and finds that open models deliver close to 90% of the capability of closed models while costing only ~16% as much.
So the core question is simple: as open models become “good enough,” how long can that premium hold—especially for developers and SMBs who feel cost every day?
A useful way to ground that question is to step away from benchmarks and look at the microeconomics of inference. According to MIT working paper, closed models still dominate usage, with ~80% of tokens flowing to closed systems on average, even though closed tokens are priced materially higher—the paper summarizes this gap as roughly ~6× on average. More importantly, the authors show that even when frontier open models can catch up on benchmark performance within months, many users continue to default to closed models. The point is not that the market is irrational; it is that a “price + benchmark” story is incomplete. Once you account for switching costs, brand and trust, organizational risk tolerance, and information frictions, model choice starts to look less like a pure capability contest and more like a bundled purchasing decision.
Most pricing debates treat “model quality” as a single axis. In real production, you are buying four things at once:
Performance: does it solve the task at the required quality bar?
Latency/throughput: can it deliver quickly enough, at scale, under concurrency?
Reliability: how often does it fail, hallucinate, or require human rescue?
Cost: not “$/1M tokens,” but total cost per completed task.
OpenRouter’s empirical study frames this market as segmented rather than commodity-like: closed models cluster in the high-cost / high-usage region, while open models dominate the low-cost / high-volume region. In their interpretation, closed models retain pricing power for mission-critical workloads, while open ecosystems absorb volume from cost-sensitive users.
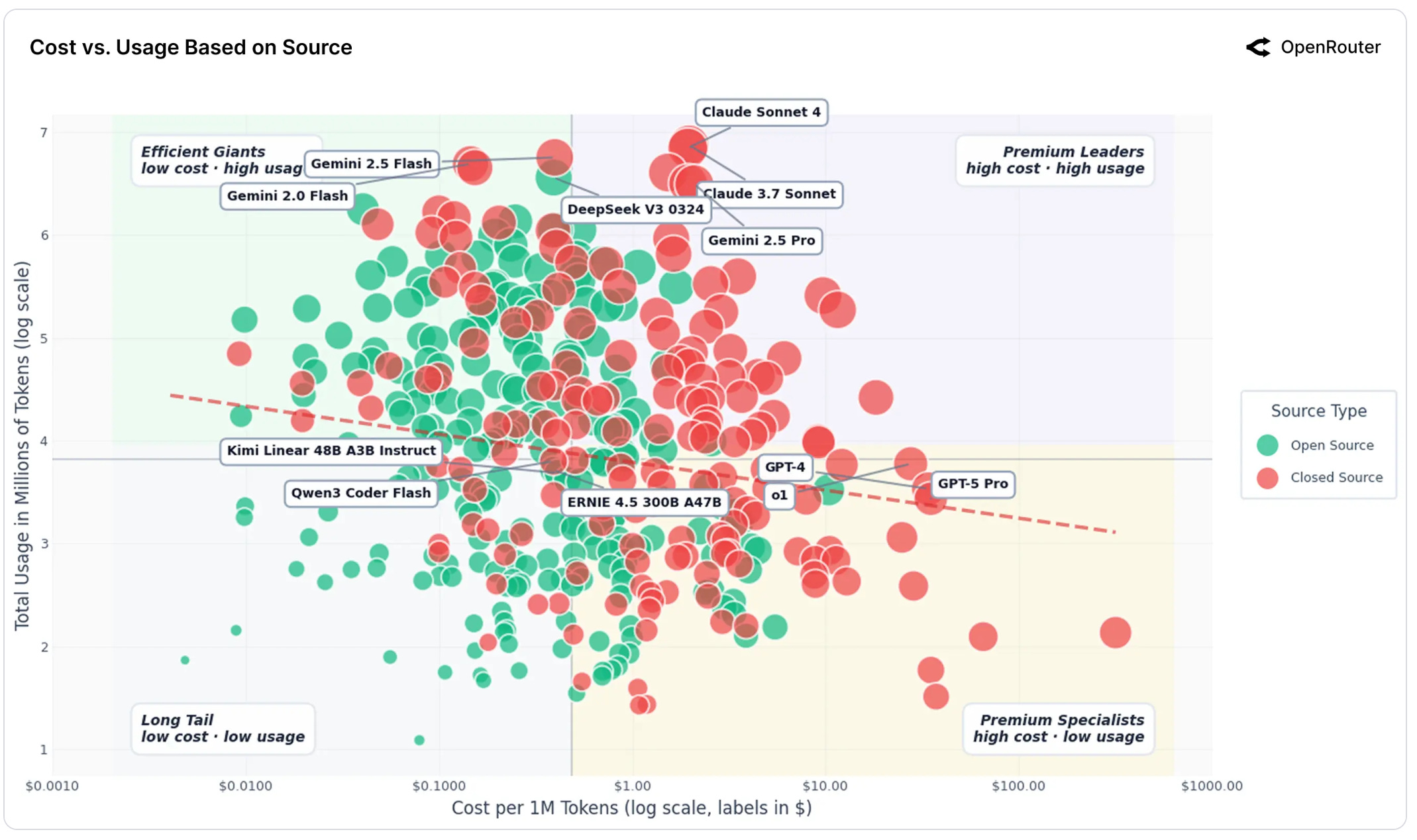
That framing matters because the premium is not really about “who is smarter.” It is about how expensive failures are and how much throughput you need. The more agentic and multi-step a workflow becomes, the more “total cost per task” starts to dwarf “headline token price.”
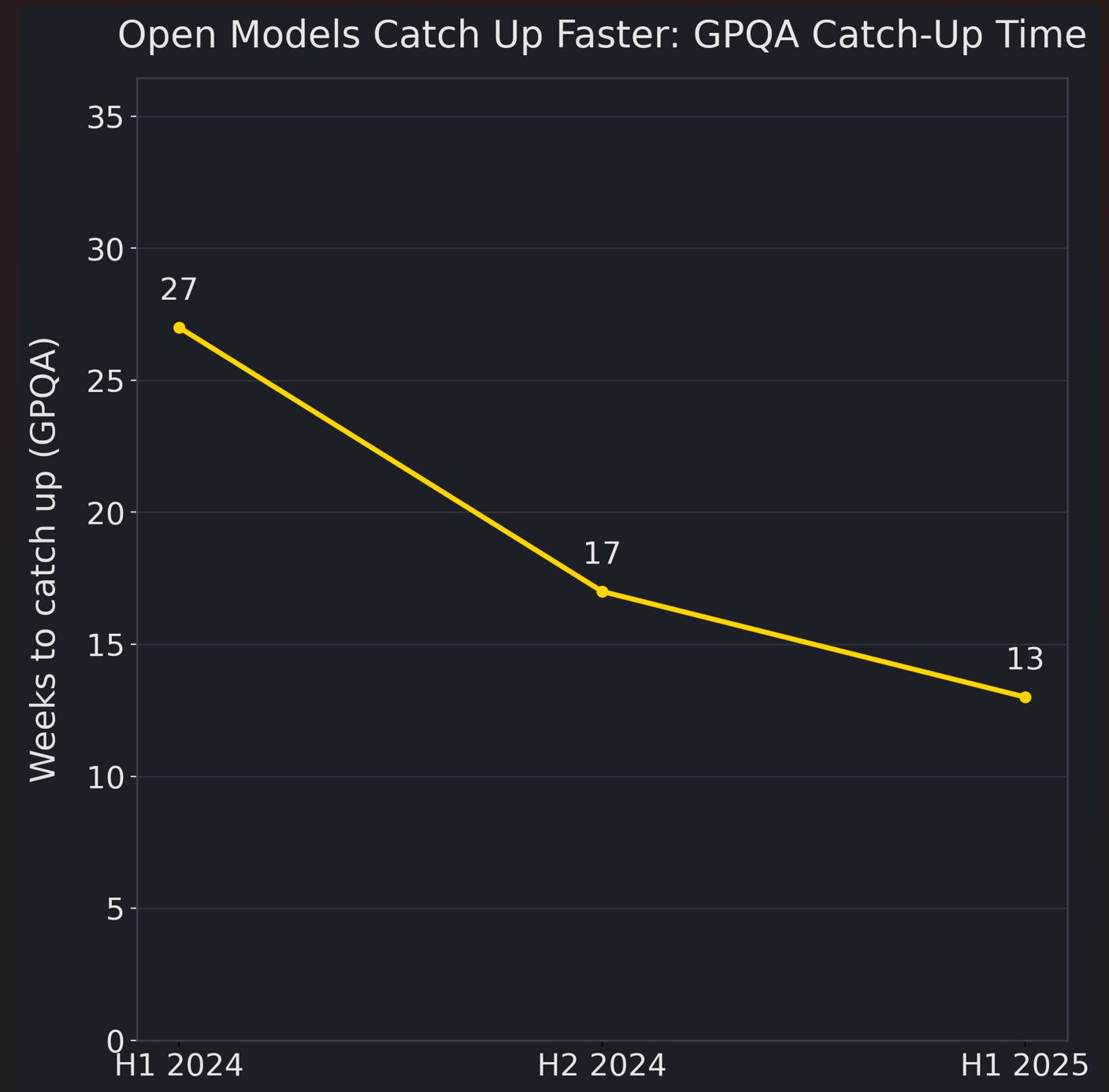
As important as the cross-sectional picture is, the timing matters even more. The same MIT paper argues that open models are not closing the gap slowly—they are doing it at an accelerating pace. Using GPQA and related benchmarks, the authors estimate a “catch-up time” and show it compressing meaningfully: roughly ~27 weeks in H1 2024, down to ~17 weeks in H2 2024, and further to ~13 weeks in H1 2025. In other words, the time it takes for frontier open models to reach comparable benchmark performance has moved toward a quarter-level cadence. That speed changes what pricing power can rest on. When performance gaps stop being long-lived moats, the premium for closed models increasingly looks less like a fee for “being smarter,” and more like a fee for lower tail risk, higher operational stability, and a clearer accountability boundary—essentially, certainty insurance.
Two routes by which open models pressure closed pricing
Route A: unit-cost substitution on the same task
This is the straightforward form of pressure: same job, lower unit cost.
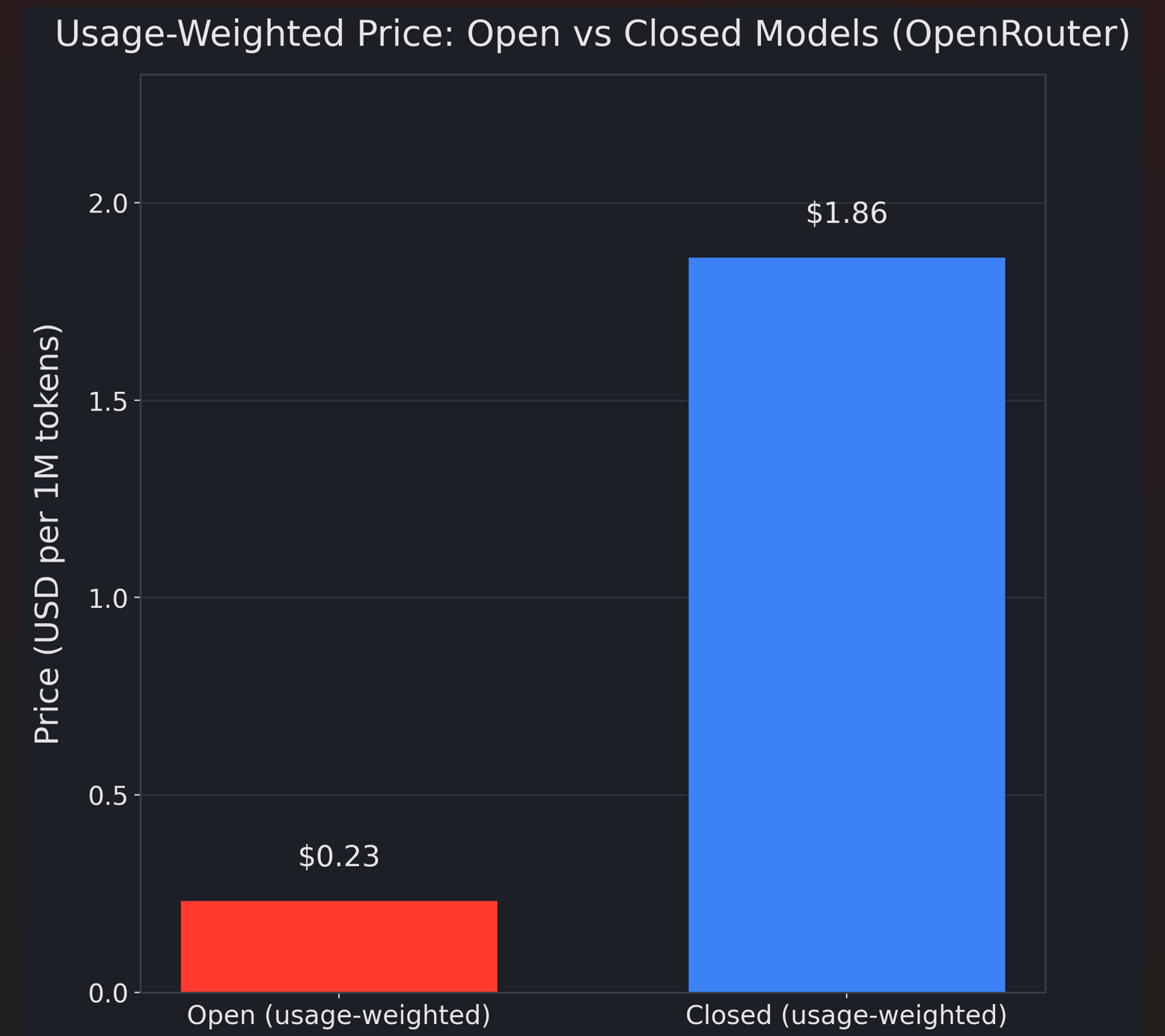
A concrete way to see it is the gap in cost structure observed in OpenRouter’s ecosystem. MIT Sloan’s write-up of the OpenRouter study summarizes a striking average: closed models cost far more per token than open models on average (they cite ~$1.86 per million tokens for closed vs ~$0.23 for open, and note that closed models represented the large majority of tokens and almost all revenue flowing through OpenRouter during the referenced period).
Even if you treat those as ecosystem averages rather than universal constants, the direction is what matters: open models repeatedly reset the “good enough” frontier at a dramatically lower effective price, and that forces closed vendors to defend the premium with something other than raw capability.
Route B: “good enough” triggers usage-density explosion—making the premium psychologically and economically unstable
The more important pressure is not substitution, but usage density.
Agentic workflows multiply calls. A single developer no longer sends a prompt and reads the answer. They run multi-step loops: plan → search → write → execute → test → patch → re-run. OpenRouter explicitly describes a shift from single-turn completion to multi-step, tool-integrated workflows in the last year.
Once a workflow uses 5–10 model calls per task, the “expensive output token” problem becomes impossible to ignore. Even if the closed model is better, the developer starts asking: Do I need the best model for every step—or only for the hardest 10% of steps?
This is where hybrid strategies emerge: closed for the final answer or critical reasoning; open for scaffolding, drafting, retrieval formatting, unit tests, refactors, or intermediate tool calls.
A useful way to quantify how much room there still is for premium compression is the paper’s strongest empirical move: “dominated choices.” The authors construct a counterfactual based on what is observable in OpenRouter’s market data. In many cases, they find an open alternative that is both cheaper and better on benchmark performance, yet demand remains with the closed model anyway. The point is not that users are irrational; it is that pricing outcomes reflect frictions—switching costs, trust, institutional inertia, and procurement constraints—as much as they reflect capability.
From that lens, the premium looks less like a pure “quality premium” and more like a premium sustained by market structure. The authors estimate that if this dominated closed-model usage were switched to the superior open alternatives, the average price paid could fall by 70%+. They then extrapolate to the broader inference market and suggest that, at 2025 scale, the implied user savings could be on the order of ~$24.8 billion. That is the core pressure point: closed-model pricing is unlikely to be reset in a single shock, but it can be squeezed persistently as substitutability improves and the plumbing matures. As routing, managed shelves, and toolchain integration lower the real switching costs, closed vendors are pushed to concentrate their premium where it can be defended—certainty and governance—or watch it be eroded by a growing set of economically dominated alternatives.
A “total task cost” example: why $/1M tokens is the wrong unit
Most pricing debates fixate on list prices—$/1M input tokens and $/1M output tokens—because they are easy to quote. But that unit is increasingly orthogonal to how real teams experience cost. What matters in production is total cost per completed task, and agentic workflows are exactly the regime where the gap between those two metrics blows out.
Consider a coding/agent task with a realistic shape:
10 steps (tool calls + reasoning turns)
each step consumes 50k input tokens (context + tool outputs) and 10k output tokens
total per task: 500k input + 100k output tokens
Now translate that into rough list-price order of magnitude.
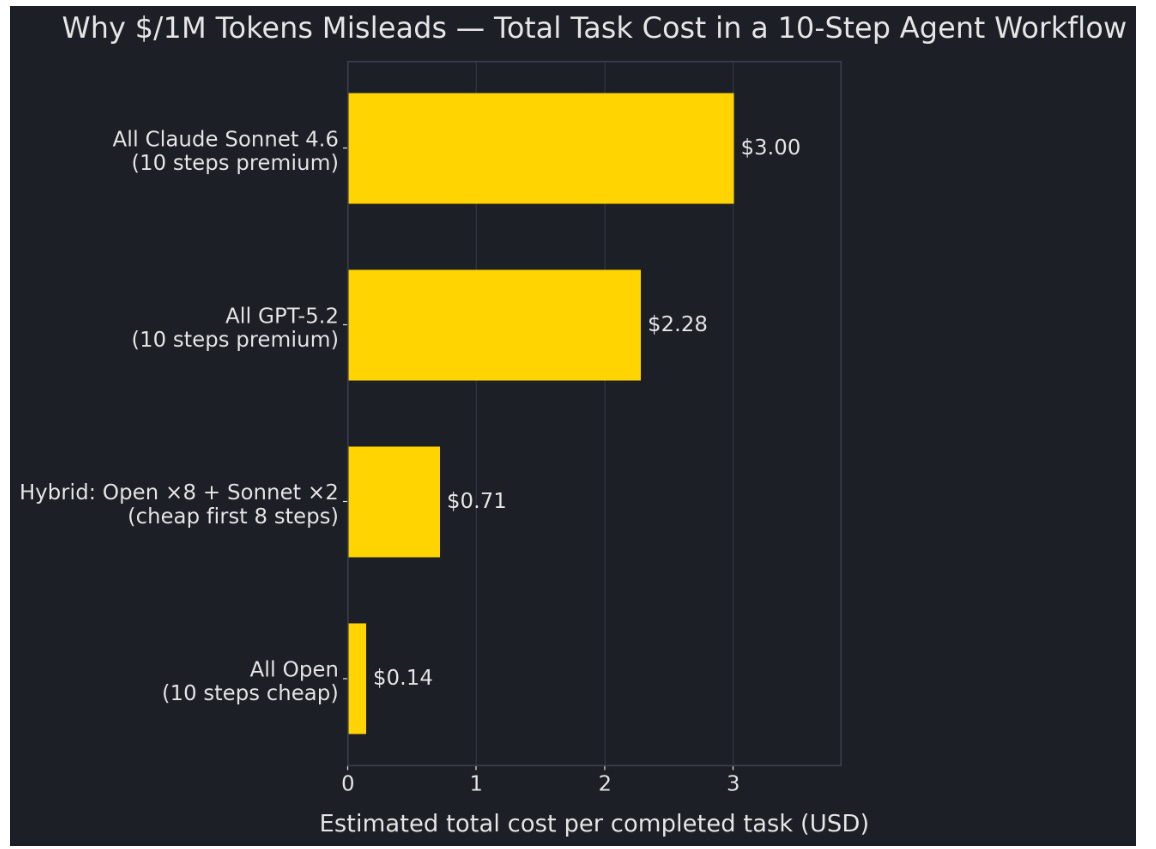
Using Claude Sonnet 4.6 as a benchmark example ($3 / $15 per 1M input/output tokens), the cost is approximately:
0.5M × $3 + 0.1M × $15 = $1.50 + $1.50 = ~$3.00 per task.
Using GPT-5.2 pricing as another reference point ($1.75 input / $14 output per 1M tokens), the same task is roughly:
0.5M × $1.75 + 0.1M × $14 = $0.875 + $1.40 = ~$2.28 per task.
To anchor the “open” side with a concrete reference point, consider the ecosystem-level average highlighted in the OpenRouter/MIT Sloan summary: open models at roughly ~$0.23 per 1M tokens (effective). Under the same 10-step workflow assumption (600k total tokens), the math is straightforward:
Cost ≈ 0.6M × $0.23 = $0.138 per task (~$0.14).
The more realistic case, though, is not “all premium” versus “all open.” It is hybrid routing, because most agent workflows naturally have a long tail of routine steps plus a small number of hard boundaries.
Using the same 10-step workflow, a simple hybrid policy—open models for the first 8 steps, and a premium model (e.g., Sonnet) for the last 2 steps—already collapses the cost curve.
The open portion covers 80% of tokens: 0.48M tokens × $0.23/1M ≈ $0.110.
The premium portion covers 20% of the workflow: 0.10M input × $3/1M + 0.02M output × $15/1M ≈ $0.60.
Total hybrid cost ≈ $0.11 + $0.60 = $0.71 per task.
This is why focusing on $/1M tokens often misleads: what actually changes behavior is the lived economics of a workflow—when a task that used to cost ~$3 drops to ~$0.7.
And that is the structural point. A hybrid workflow can preserve premium-grade reliability exactly where it matters, yet still cut the total task cost by roughly 75% versus running the entire workflow on Sonnet (~$3.00). Once teams see a gap like $0.71 vs $3.00 on a workflow they run thousands of times, “mixed-model routing” stops being an optimization trick and starts looking like the obvious operating mode.This is where the economics becomes non-linear. Agent workflows rarely finish in a single pass. If a cheaper model occasionally needs a second try, it can still win on total cost. The premium holds only if it materially reduces rework cycles, debug time, and the hidden tax of uncertainty—what teams experience as: “We can’t trust it, so we have to check everything.” In other words, the premium is ultimately a price on variance.
What closed models can still defend—and what they likely cannot
Closed models still have defensible territory, but it is not “everything everywhere.” It is narrower—and more valuable—than that.
Where closed models can still defend a premium is where buyers are effectively purchasing certainty: enterprise trust, compliance posture, and a clearer liability boundary. In those settings, the model is not just a reasoning engine; it is a vendor-backed component inside a governed system. The value is not only higher average quality, but lower tail risk—fewer silent failures that surface later as incidents.
They also retain advantages where the “uncertainty cost” dominates token cost: workflows that require consistent tool use, stable behavior under long context, fewer brittle edge cases, and strong operational reliability. In practice, this is why closed models tend to remain sticky in high-stakes programming and technical workflows, where a single wrong change can create cascading downstream cost.
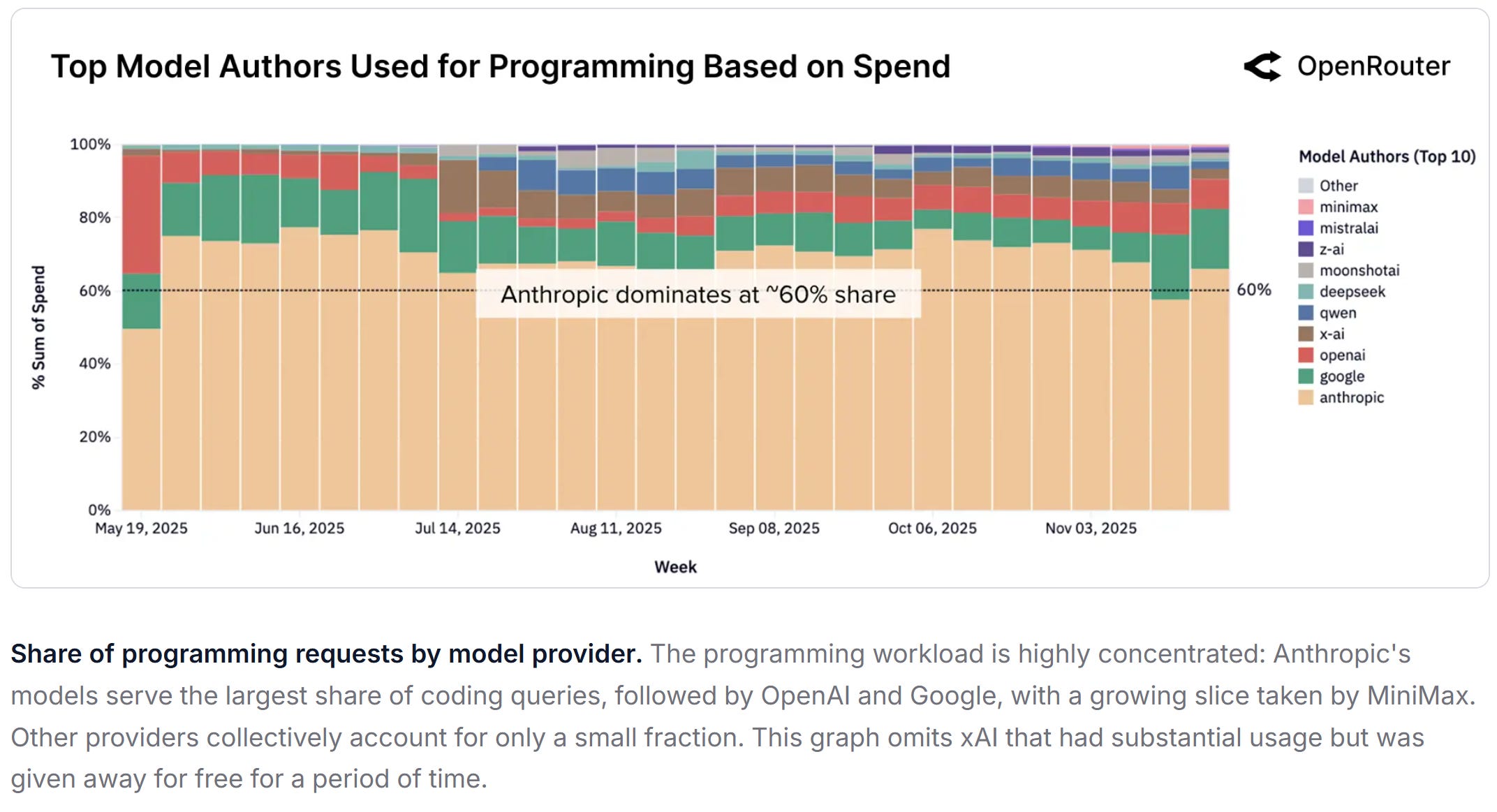
But closed models will struggle to defend uniform premium pricing across every step of an agentic workflow. As usage becomes multi-step and tool-driven, many calls are not “mission critical.” They are scaffolding: drafting, refactoring, formatting, retrieval cleanup, unit tests, log parsing. Those steps reward throughput and cost efficiency more than absolute best-in-class intelligence. Once open models become “good enough” there, the premium model’s role shifts upward—and the premium share of tokens shrinks.
The most important implication is that closed vendors will increasingly need to justify premiums explicitly in terms of measurable reductions in uncertainty cost: fewer interventions, fewer retries, fewer escalations, and more predictable outputs. Premium pricing remains viable—but only where it can be defended as insurance, not as a default tax on every token.
The equilibrium is a barbell: open wins volume, closed defends “certainty”
The most plausible outcome is not a clean regime change where open models “replace” closed models. It is a gradual re-pricing of where the premium can be charged—and where it cannot.
Closed models will remain defensible in the slices of work where failure is expensive and where buyers are purchasing a bundle of reliability: fewer silent errors, fewer production incidents, fewer escalations, and clearer accountability. That is why regulated enterprise workflows, security-sensitive agent systems, and high-stakes engineering tasks will continue to support premium pricing. In these environments, cheaper tokens matter less than the expected cost of being wrong.
But a growing share of day-to-day usage—especially among developers and SMBs—will keep drifting toward low-cost open models, for a simple economic reason: most real workflows contain a large volume of intermediate steps whose value is throughput, not perfection. When an open model crosses the “good enough” threshold for those steps, it absorbs the volume. The premium model does not disappear; its role narrows. It migrates toward the parts of the workflow where trust is purchased, not assumed.
This is what premium compression looks like in practice. List prices can remain high, yet the premium is applied to a smaller portion of total tokens, and it must be justified with measurable reductions in uncertainty cost. The market does not flip; it re-allocates. Closed models keep the high-stakes margin. Open models take the high-volume middle. The premium survives—but it becomes less universal and more conditional.
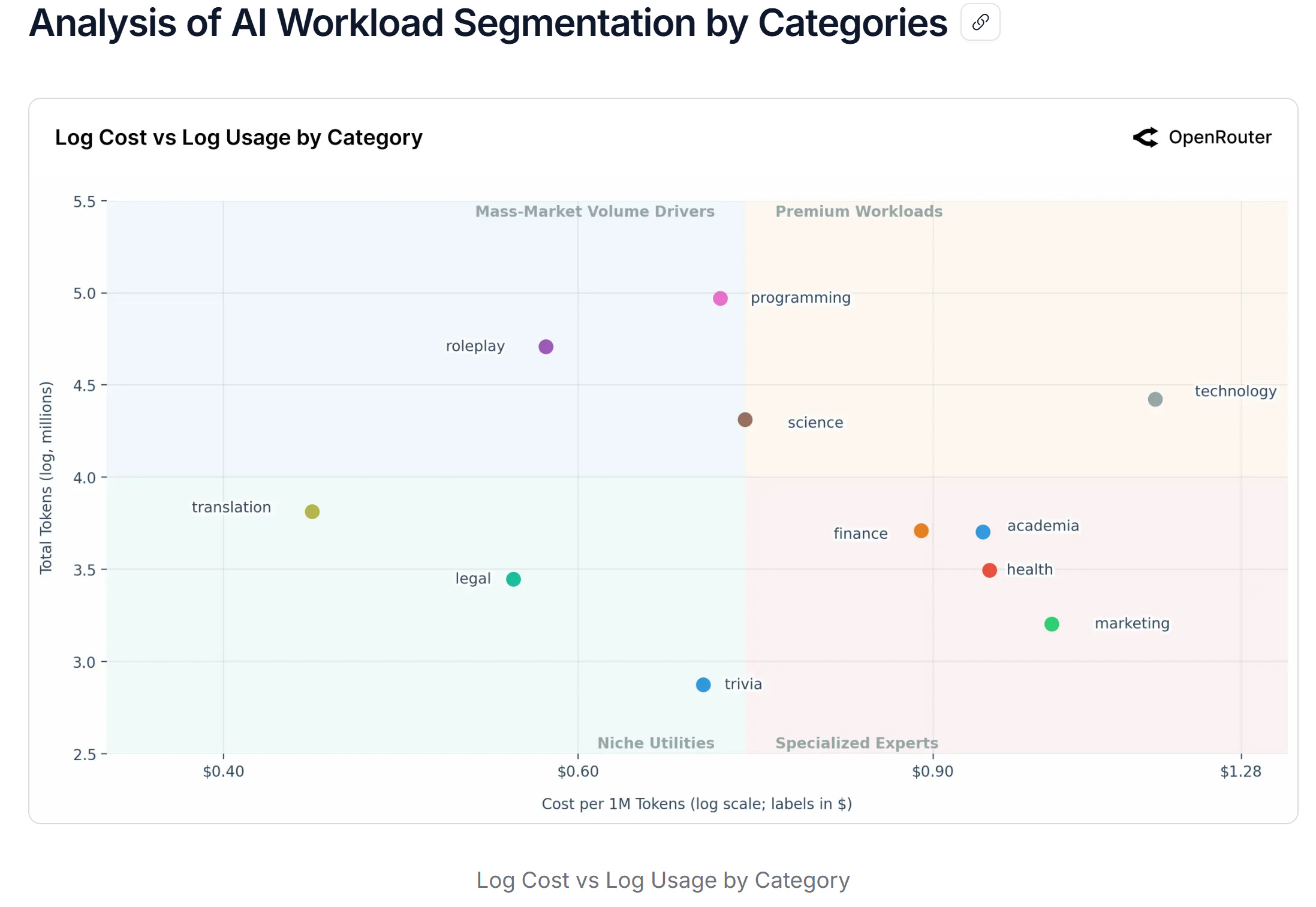
The mechanism: routing, tiered defaults, and platform-level governance rewrite pricing power
Three shifts look highly likely, and together they point to a single implication: pricing power moves from “the model” to “the workflow,” and from “capability” to “certainty.”
First, mixed-model routing becomes the default posture in developer tooling. As soon as tools have access to multiple providers, the rational behavior is to allocate calls dynamically: cheaper models handle the bulk, premium models are reserved for the turns where mistakes are costly. This is not a niche optimization; it becomes the standard configuration once multi-step agent workflows become mainstream.
Second, platforms will ship tiered routing as a product feature, not a hack. Defaults will increasingly encode a simple rule: use low-cost models for routine steps, and escalate to a premium model only when the workflow hits a hard boundary—verification, debugging, final synthesis, or high-risk tool execution. This reduces average cost and improves throughput without forcing users to micromanage model choice.
Third, enterprises will standardize procurement through managed shelves (AWS/Azure/GCP) because it keeps governance constant while making models swappable. They want one set of controls—identity, logging, data boundaries, compliance checks—regardless of which model sits underneath. Once governance becomes platform-level rather than model-level, switching models stops being a full procurement event and starts looking like a configuration change.
If these shifts play out—and they likely will—the implication for Claude and ChatGPT is not collapse, but a narrower and more defensible premium. Closed models increasingly get paid for certainty: lower variance, stronger guarantees, clearer responsibility boundaries. That is where the premium remains rational. But it becomes harder to sustain a uniform $15–$25 per 1M output-token regime as a default baseline, because the default workflow will increasingly route around it.
Source:
1、State of AI
An Empirical 100 Trillion Token Study with OpenRouter
https://openrouter.ai/state-of-ai?utm_source=chatgpt.com
2、AI Model Rankings
https://openrouter.ai/rankings
3、The Latent Role of Open Models in the AI Economy
https://mitsloan.mit.edu/ideas-made-to-matter/ai-open-models-have-benefits-so-why-arent-they-more-widely-used?utm_source=chatgpt.com
