
Huawei’s Interconnect Bet
Why UnifiedBus, all-optical interconnects, and SuperPoDs are the real core of Huawei’s AI compute strategy

Huawei’s interconnect bet is a systems-engineering response to chip constraints: weaker single chips, larger scale-up domains, all-optical links, bigger memory pools, software-stack adaptation, and a domestic demand loop that can turn usable compute into improving compute.
This essay is part of China AI System Series.
Executive Summary
Huawei’s real AI compute bet is interconnect. Ascend should not be evaluated only as a single-chip substitute for Nvidia GPUs. The strategic question is whether Huawei can use UnifiedBus, all-optical interconnects, SuperPoDs, and SuperClusters to organize many weaker NPUs into system-level effective compute.
AI compute competition is moving from chips to systems. Frontier AI training depends on single-chip performance, HBM capacity and bandwidth, interconnect architecture, distributed-training software, reliability, and long-duration operations. A weakness in any one layer can turn paper FLOPs into unusable compute.
Nvidia’s advantage is already a system advantage. Nvidia’s moat is not only B200 or GB200. It is the integration of GPU performance, HBM, NVLink, NVSwitch, InfiniBand, NCCL, CUDA, TensorRT, cloud reference architectures, and global developer defaults. Huawei’s challenge is to build a Chinese AI factory under semiconductor constraints.
UnifiedBus is Huawei’s attempt to turn large clusters into logical machines. Its goal is to reduce hierarchy across nodes, cabinets, and clusters through unified protocols, resource pooling, all-optical interconnects, and larger scale-up domains. The point is to make thousands of NPUs behave less like isolated devices and more like a coordinated compute system.
CloudMatrix 384 and Atlas 950 show the direction of Huawei’s system roadmap. CloudMatrix 384 uses 384 Ascend 910C chips, all-to-all topology, all-optical interconnects, about 300 PFLOPS BF16 compute, 49.2 TB HBM, and 1,075,200 Gb/s scale-up bandwidth. Atlas 950 pushes the logic to 8,192 Ascend 950DT chips, 1,152 TB memory, and 16 PB/s interconnect bandwidth.
Huawei’s route remains costly, difficult, and unproven at the frontier, but strategically serious. It faces lower energy efficiency, higher system complexity, weaker software ecology, and uncertain frontier-training validation. Its significance lies in bringing China’s strengths in optical networks, data centers, telecom infrastructure, system integration, domestic demand, and forced substitution into AI compute competition.

A Panorama of Rivers and Mountains (千里江山图)
By Wang Ximeng, Northern Song Dynasty
Its interconnected mountains, rivers, roads, bridges, and settlements echo the central theme of this essay: Huawei Ascend as an organized computing system rather than a standalone chip.
Before AI becomes a model, it first becomes a physical system.
It becomes cabinets, optical modules, power cables, cooling loops, memory stacks, switches, racks, software libraries, and engineers trying to keep thousands of accelerators synchronized through long training runs. The public debate often begins with the chip: H100, B200, Ascend 910C, Ascend 950DT. But inside a real AI data center, the chip is only one component inside a larger machine. The decisive question is how all those components are connected, scheduled, cooled, powered, repaired, and made usable by software.
This is why the discussion about Huawei’s AI compute strategy should not start from a single benchmark number. A benchmark can tell us something about one chip. It cannot tell us whether thousands of chips can behave like one compute system. It cannot tell us whether memory bottlenecks can be reduced, whether communication overhead can be controlled, whether failures can be recovered from, whether software frameworks can keep the cluster saturated, or whether customers can actually deploy workloads on the platform without turning every project into a custom engineering war.
Seen from this angle, Huawei’s Ascend strategy is less a story about one Chinese chip trying to catch one Nvidia chip. It is a story about how China is trying to turn constrained chips into usable AI infrastructure. That effort runs through the chip, but it does not stop at the chip. It runs through interconnect architecture, optical networking, memory pooling, SuperPoDs, software adaptation, cloud services, telecom operators, government-enterprise deployment, and the domestic demand that forces the system to keep improving.
Nvidia has already shown what the winning form of AI infrastructure looks like. It is not merely a GPU company selling accelerators into servers. It has turned GPUs, HBM, NVLink, NVSwitch, InfiniBand, CUDA, NCCL, TensorRT, cloud architecture, and developer habits into a complete AI factory. That is the standard Huawei is responding to. Huawei cannot reproduce that system overnight, and it cannot erase Nvidia’s single-chip and software-ecosystem advantages through slogans. Its route is heavier, more constrained, and more engineering-intensive.
But that is exactly why the Huawei route deserves close attention. When the optimal system is not fully available, the strategic problem changes. The question becomes whether a country can build a second-best system that is available, deployable, controllable, and capable of iteration. In China’s case, that means using more silicon, more electricity, more optical interconnects, larger memory pools, and more system engineering to create AI compute that is good enough to support real workloads and improve through use.
This is the real meaning of Huawei’s interconnect bet. It is not a side issue. It is the place where China’s AI compute strategy tries to convert weakness into organization.
The first essay focused on narrative misjudgment: some Western analyses interpret China’s AI compute path as “weaker chips + more quantity + traditional networks + fragmented clusters.” From that framing, they naturally conclude that even if China can assemble impressive paper FLOPs, it will still struggle to form truly trainable, inference-capable, and operationally manageable frontier AI compute. This judgment may look technically sophisticated, but it misses the most important layer of Huawei’s actual path: Huawei is not simply compensating for chips. It is reconstructing how chips are organized with one another.

The second essay moves into the real technical layer. The core of Huawei’s Ascend route is not only Ascend 910C, 950DT, or 960 themselves. It is how these chips are connected, how they are organized into larger computing units, how they are scheduled as a logical system, and how the single-chip gap is converted into a systems-engineering problem. In other words, the key variable in Huawei’s AI compute strategy is not the benchmark score of any single chip. It is whether UnifiedBus, all-optical interconnects, CloudMatrix, Atlas SuperPoD, and SuperCluster can organize more NPUs into system-level effective compute.
Huawei’s real bet is interconnect.
Here, “interconnect” does not mean ordinary networking equipment. Nor is it a supporting accessory inside the data center. It has become the core structure of AI compute infrastructure. As large-model training advances, the bottleneck is no longer only compute density. It is the system-level coordination among memory, communication, synchronization, scheduling, failure recovery, and the software stack. Nvidia’s success has never been the success of a single GPU. It is a system advantage built from GPUs, HBM, NVLink, NVSwitch, InfiniBand, NCCL, CUDA, cuDNN, TensorRT, and the entire data-center architecture. If Huawei wants to keep advancing China’s AI compute under process-technology constraints, it must find a compensation mechanism in another dimension. That dimension is interconnect.
1. The Core Unit of AI Compute Competition Is Expanding from Chips to Systems
To understand Huawei’s interconnect route, we first need to understand why large-model training is not simply a matter of “more compute is better.” In ordinary intuition, AI training looks like a giant computational task: as long as there are enough chips and enough operations, the model should train faster. But real large-model training does not work that way. Model parameters, gradients, activations, intermediate states, and optimizer states constantly move across different accelerators. Each card does not merely compute in isolation. It must also exchange information with other cards. The larger the model and the higher the degree of training parallelism, the more important communication and synchronization become. At the ten-thousand-card level, the system bottleneck is often no longer how fast a single matrix multiplication can run, but whether data can arrive on time, whether gradients can be synchronized reliably, whether tasks can be partitioned efficiently, and whether failures can be recovered from quickly.
This is why HBM matters. Large-model training and inference require frequent access to model weights and intermediate results. If the compute unit is powerful but memory bandwidth is insufficient, the compute unit will wait for data. No matter how high the paper FLOPs are, the system may fail to reach its potential because it cannot be “fed” fast enough. The advantage of Nvidia’s new-generation GPUs lies not only in stronger Tensor Cores, but also in the continuous improvement of HBM capacity and bandwidth. This is also why chip-to-chip interconnect matters. No matter how large the HBM of a single GPU or NPU is, it cannot hold ever-larger models and increasingly complex training states by itself. Models must be partitioned across multiple cards, and often across multiple nodes, cabinets, and clusters. Every cross-card communication creates latency. Every cross-node synchronization adds overhead. If the interconnect is too weak, adding more chips can actually produce lower efficiency. On paper, a 1,000-card system may have enormous compute. In real training, it may be able to use only a small fraction of it.
So the core unit of frontier AI compute competition has expanded from “the chip” to “the compute system.” A truly usable AI training system requires at least five layers of capability:
First, single-chip compute and energy efficiency;
Second, HBM capacity and bandwidth;
Third, interconnect across the chip, between chips, inside nodes, between nodes, and across cabinets;
Fourth, the distributed-training software stack;
Fifth, long-duration reliability and operational capability.
A weakness in any one layer can turn paper compute into ineffective compute. This is also the technical fact that the ChinaTalk article correctly identifies: not all compute is created equal. But the problem is that it takes this fact and continues toward the conclusion that “China’s weaker-chip stacking cannot produce effective frontier compute,” without fully seeing that Huawei is trying to reorganize the weaknesses of the first two layers through the third layer: interconnect architecture.
To understand why Huawei is betting on interconnect, we also need to understand Nvidia’s real moat. Nvidia is certainly a GPU company. But today, Nvidia is far more than a GPU company. It sells an AI factory architecture. At the bottom layer are GPUs. In the middle are NVLink, NVSwitch, InfiniBand, Spectrum-X, BlueField, Grace Hopper, GB200, and future Rubin systems. At the upper layer are CUDA, NCCL, cuDNN, cuBLAS, TensorRT, Triton, NGC, Megatron-LM, and the priority adaptation of nearly every mainstream AI framework to Nvidia. Nvidia’s advantage is not that one layer leads in isolation. Its advantage is that every layer reinforces every other layer. NVLink enables high-speed direct communication among GPUs. NVSwitch organizes multiple GPUs into a larger high-speed interconnect domain. InfiniBand supports communication across servers, cabinets, and large-scale clusters. NCCL optimizes distributed-training communication such as All-Reduce, All-Gather, and Reduce-Scatter at the software layer. CUDA allows developers to avoid directly handling low-level hardware details. cuDNN and cuBLAS optimize a large number of common operators. TensorRT turns inference deployment into a high-performance toolchain.
Therefore, Nvidia’s advantage cannot be summarized simply as “B200 is powerful.” B200 is powerful because it is embedded in a complete system. It is powerful as a single chip, but it is also powerful because it can be placed inside a system such as NVL72, organized through NVLink and NVSwitch, and then expanded into larger clusters through InfiniBand and NCCL. It is strong in hardware, but also in software. It is strong in product design, but also in the fact that developers default to it. This means that if Huawei merely builds a “domestic GPU substitute chip,” it will be almost impossible to truly challenge Nvidia. Even if one generation of Ascend approaches some metrics of H100 or B200, it will still struggle to become a mainstream large-model training platform if interconnect, software, frameworks, tuning tools, and the ecosystem lag behind.
Huawei understands this clearly. That is why the Ascend route has never been a single-chip route. It is a full-stack route.
The chip is only the first layer.
Atlas servers and SuperPoDs are the second layer.
UnifiedBus is the third layer.
CANN, MindSpore, PyTorch on Ascend, and ModelArts are the fourth layer.
Cloud services, telecom operators, government and enterprise customers, and industry-model deployment are the fifth layer.
This system is still immature, and it remains far less complete than Nvidia’s. But its direction is very clear: since Huawei cannot replicate Nvidia’s single-chip performance and CUDA ecosystem in the short term, it must search for compensation through system organization. Especially under conditions where China cannot reliably obtain the most advanced Nvidia systems, Huawei’s objective is not to build “the world’s best AI system.” It is to build “an AI system that China can obtain, deploy, and iterate.”
That objective is what makes interconnect so important.
2. The Real Meaning of UnifiedBus Is to Make a Large Cluster Behave as Much as Possible Like One Logical Machine
It is not accidental that Huawei has placed Lingqu, or UnifiedBus, at the center of its AI SuperPoD architecture. Traditional AI clusters usually have obvious hierarchy. Communication between cards inside a server is the fastest. Communication between nodes is slower. Communication across cabinets is more complex. Communication across machine rooms or clusters requires even higher-level networking. This hierarchy fits traditional data-center architecture, but it is not ideal for large-model training. Model parallelism, tensor parallelism, pipeline parallelism, expert parallelism, and data parallelism all require continuous data exchange across many cards. The more complex the hierarchy, the harder the scheduling, the less predictable the latency, and the more difficult the failure recovery.
The goal of UnifiedBus is to flatten this hierarchy as much as possible. It is not trying to make external networking faster than HBM, and it cannot violate physical laws. Instead, it aims to use unified protocols, unified addressing and communication semantics, all-optical interconnects, resource pooling, and a larger interconnect domain to organize multiple physical machines into a more tightly coupled compute system. Huawei’s official description of Atlas 950 SuperPoD is that UnifiedBus allows thousands of compute nodes to operate like one computer, supporting large-scale AI training and high-concurrency inference. This shows that Huawei’s target is not a traditional cluster, but a single logical machine. When Huawei released Atlas 950 and Atlas 960 SuperPoD in 2025, it also explicitly described SuperPoD as a single logical machine composed of multiple physical machines, capable of learning, thinking, and reasoning as one whole. Atlas 950 SuperPoD contains 8,192 Ascend NPUs, while Atlas 960 SuperPoD contains 15,488 Ascend NPUs. The core metrics cover NPU count, total compute, memory capacity, and interconnect bandwidth.

The technical intention behind this is clear: if a single NPU is not powerful enough, put many NPUs into a larger compute domain; if traditional network hierarchy creates loss, use a unified bus-like architecture to reduce hierarchical boundaries; if model training requires frequent synchronization, incorporate communication paths, protocol stacks, and resource scheduling into the system design; if single-machine memory is insufficient, use a larger system memory pool to support larger models and higher parallelism.
The core objective of Lingqu is to create an interconnect experience closer to host-bus-level communication. It connects thousands or even tens of thousands of accelerator chips through a unified high-speed communication system into a “flat network,” allowing them to collaborate more like different cores inside one machine. It emphasizes bus-level interconnect, peer-to-peer coordination, resource pooling, protocol unification, and large-scale high-availability networking.
This is the fundamental difference between Huawei’s route and ordinary “card stacking.” Ordinary card stacking increases the number of devices. UnifiedBus tries to change the relationship among those devices. Ordinary card stacking answers the question of “how many cards are there?” UnifiedBus answers the question of “can these cards work like one system?”
Huawei’s logic is straightforward: single-chip weakness cannot be denied; lower energy efficiency cannot be denied; the CUDA ecosystem gap cannot be denied. But if more NPUs can be placed into a larger interconnect domain, if the system memory pool can be expanded, if cross-node communication overhead can be reduced, and if UnifiedBus can make multiple physical machines behave more like one logical machine, then the single-chip gap is no longer a simple linear constraint. It becomes a problem that can be partially compensated through systems engineering.
This is the essence of Huawei’s SuperPoD route.
3. From CloudMatrix 384 to Atlas 960: Huawei Is Trying to Turn the AI Data Center into a Larger Machine
CloudMatrix 384 is the first-stage validation of Huawei’s interconnect bet. This system uses 384 Ascend 910C chips. It is not a high-density system built from 72 stronger GPUs. Its path is clear: use more chips to compensate for the single-chip gap, then use all-optical interconnects and an all-to-all topology to organize those chips into a high-bandwidth scale-up domain. SemiAnalysis made the point directly: Huawei’s chips are roughly one generation behind, but its scale-up architecture may be one generation ahead of current Nvidia and AMD products in the market. CloudMatrix 384 connects 384 Ascend 910C chips through an all-to-all topology, using roughly five times as many Ascend chips to offset the fact that a single chip delivers only about one-third of Blackwell’s performance.
CloudMatrix 384 can deliver about 300 PFLOPS of dense BF16 compute, exceeding the roughly 180 PFLOPS of GB200 NVL72.
It has about 49.2 TB of HBM capacity, compared with about 13.8 TB for GB200 NVL72.
Its aggregate HBM bandwidth is about 1,229 TB/s, compared with about 576 TB/s for GB200 NVL72.
Its scale-up bandwidth is about 1,075,200 Gb/s, compared with about 518,400 Gb/s for GB200 NVL72.
Tom’s Hardware’s comparison based on SemiAnalysis data also shows that CloudMatrix 384 has system-level advantages in BF16 compute, HBM capacity, HBM bandwidth, and scale-up bandwidth. But the cost is also clear: power consumption is much higher. The system consumes about 559 kW, compared with about 145 kW for GB200 NVL72.
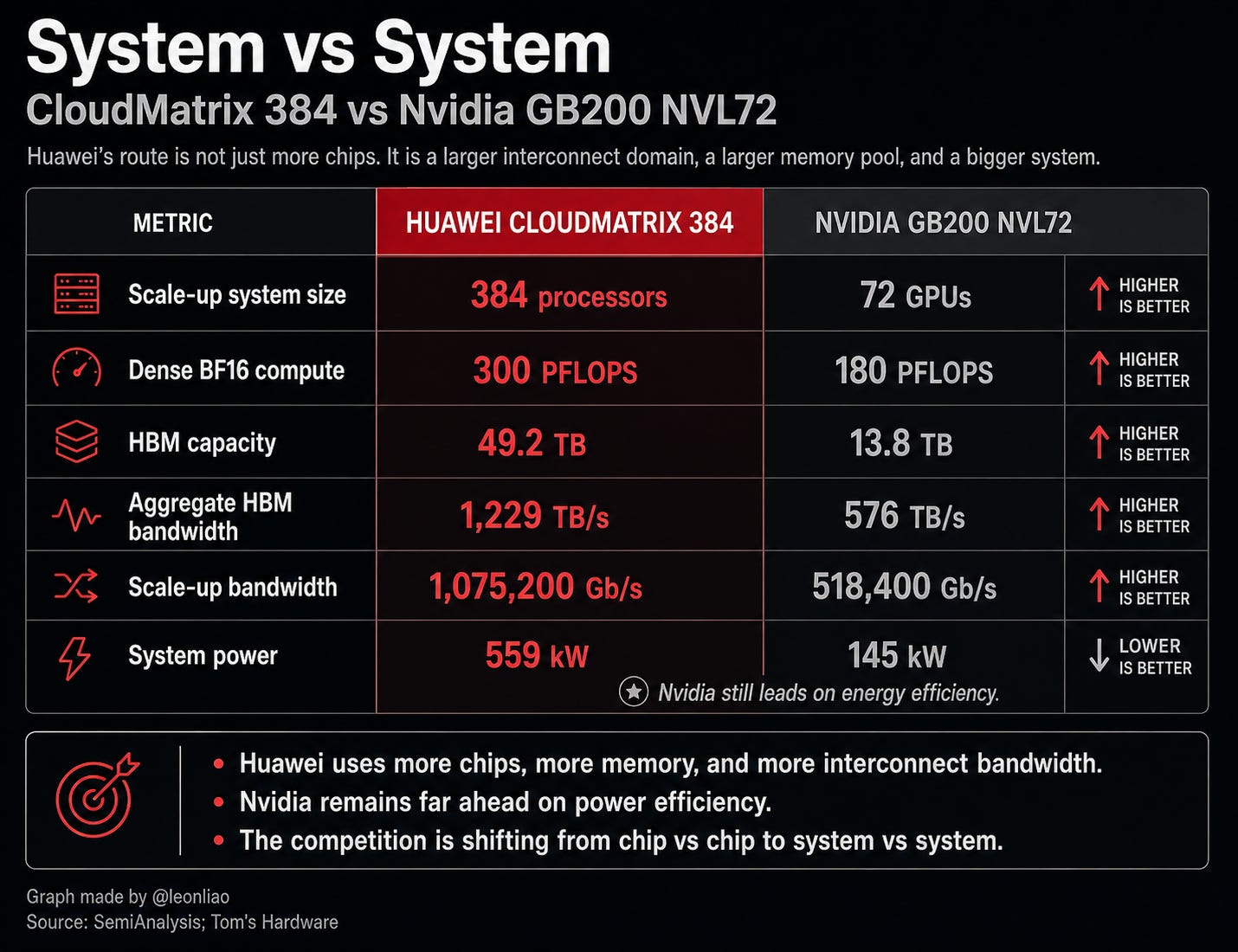
The most important point in these numbers is not that Huawei is “stronger than Nvidia.” That would be too simple, and it would not be accurate. What these numbers really show is that Huawei has begun converting single-chip weakness into system-level compensation: more chips, more memory, a larger interconnect domain, higher power consumption, and more complex engineering in exchange for high-level system compute under available conditions.
From an architectural perspective, the key to CloudMatrix 384 is not only “384 Ascend 910C chips,” but how those chips are connected. Tom’s Hardware reported that CloudMatrix 384 is a 16-rack system. Twelve compute racks each contain 32 accelerators, while four network racks are used for high-bandwidth interconnect. Communication inside the system and between racks relies entirely on optical interconnects, using 6,912 800G LPO optical modules to create high-bandwidth, low-latency communication. This shows that Huawei is not crudely stacking chips inside a traditional server network. It is putting optical interconnects, communication racks, an all-to-all topology, and system software into one architecture.
The value of CloudMatrix 384 is not that it has already solved every problem in large-model training. Its value is that it provides an observable engineering sample: under advanced-process constraints and single-chip weakness, a Chinese company can use optical interconnects and system integration to organize more NPUs into a large system with real training and inference value. This is the first step in Huawei’s interconnect bet.
If CloudMatrix 384 is the first stage, then Atlas 950 SuperPoD is the next system unit Huawei really wants to show. Atlas 950 SuperPoD supports up to 8,192 Ascend 950DT chips, twenty times the scale of Atlas 900 A3 SuperPoD. A full configuration includes 160 cabinets, of which 128 are compute cabinets and 32 are communication cabinets, occupying about 1,000 square meters, all connected through all-optical interconnects. Its target compute is 8 EFLOPS FP8 and 16 EFLOPS FP4, with 16 PB/s interconnect bandwidth and 1,152 TB of memory. It is planned for launch in the fourth quarter of 2026.
This is really about enlarging the basic unit of AI compute. 384 Ascend 910C chips are already no longer an ordinary server node. 8,192 Ascend 950DT chips are even less a natural extension of a traditional cluster. They are a data-center-scale compute unit. The scale itself shows that Huawei wants SuperPoD to become something like a “system-level chip” for future AI infrastructure.
That may sound exaggerated, but it captures the direction of Huawei’s design. In the past, the chip was the basic unit of computing. Later, the multi-card system inside one server became the training unit. Then DGX, NVL72, and SuperPOD became larger AI training units. Huawei is now trying to push that scale even further, turning an Atlas 950-style SuperPoD into a logical machine that can be called, scheduled, and managed by the software stack. So the key to Atlas 950 is not just 8 EFLOPS or 16 PB/s. It is the structure: 128 compute cabinets plus 32 communication cabinets, all-optical interconnects, unified protocols, unified scheduling, and unified resource pools. Its design assumption is that future AI compute will not happen inside one server, or even inside dozens of servers, but inside a large-scale physical system. That physical system itself must be designed as a product.
Atlas 960 SuperPoD continues to expand this logic. Huawei disclosed that Atlas 960 SuperPoD will support up to 15,488 Ascend 960 chips, composed of 220 cabinets, of which 176 are compute cabinets and 44 are communication cabinets. It will occupy about 2,200 square meters and is planned for launch in the fourth quarter of 2027.
Huawei says Atlas 960 SuperPoD will double Atlas 950 in compute, memory capacity, and interconnect bandwidth. Its target metrics are 30 EFLOPS FP8, 60 EFLOPS FP4, 4,460 TB of memory, and 34 PB/s of interconnect bandwidth.
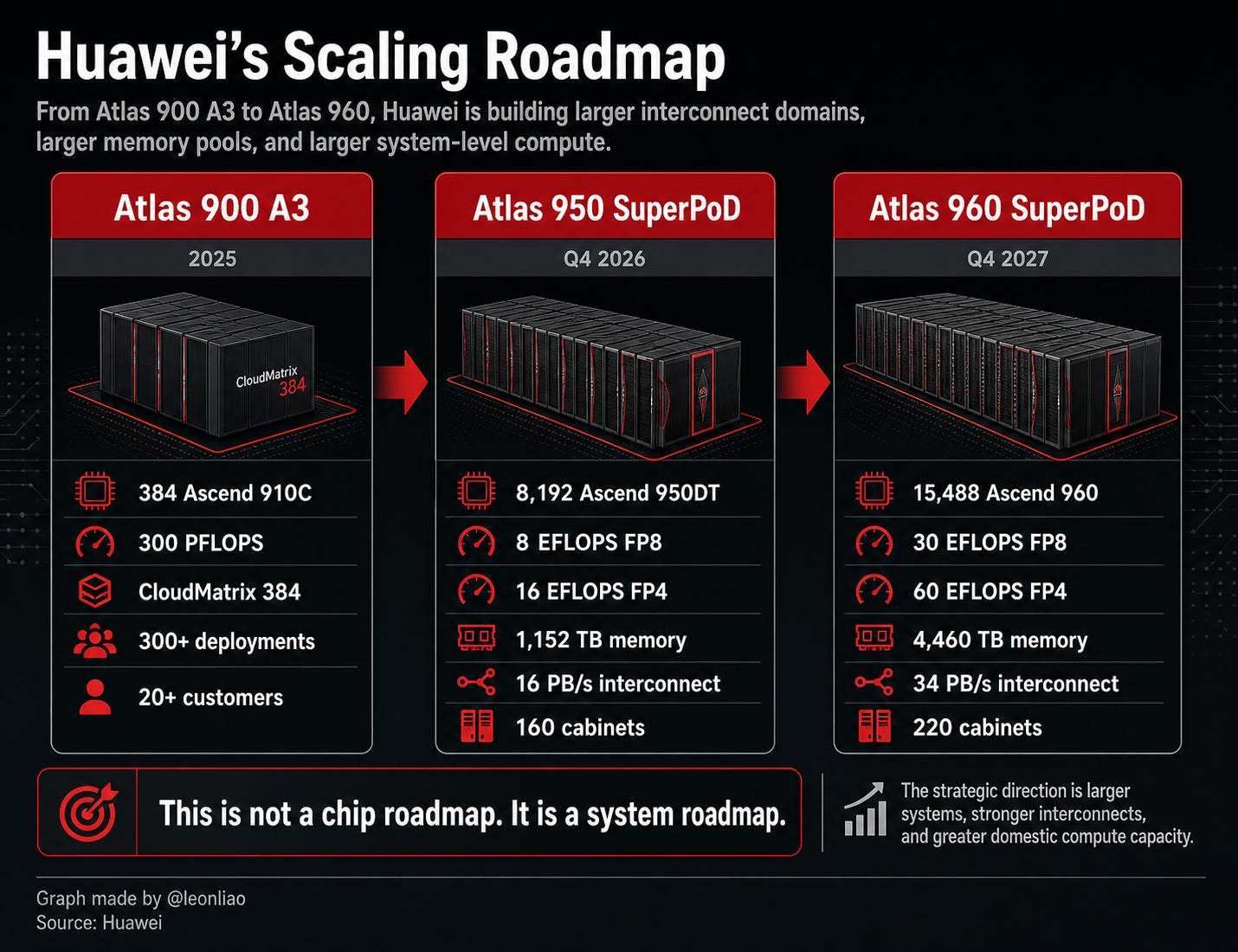
Huawei has gone even further by announcing Atlas 950 SuperCluster and Atlas 960 SuperCluster. Atlas 950 SuperCluster will be composed of multiple Atlas 950 SuperPoDs and scale to more than 500,000 Ascend NPUs. Atlas 960 SuperCluster will scale to more than one million Ascend NPUs. Huawei says these SuperClusters are built from multiple SuperPoDs and are intended to form larger-scale compute clusters.
Of course, a roadmap is not a measured result. Launch-event specifications are not long-term training utilization. For a system with one million NPUs, the truly difficult problems are power supply, cooling, connection, monitoring, scheduling, fault tolerance, upgrades, maintenance, how to keep training jobs stable over weeks or months, and how to make software frameworks truly use this scale. But from the perspective of strategic intent, these numbers already show Huawei’s direction: it wants to turn the AI data center itself into a larger machine.
This resembles traditional supercomputing in some ways, but AI training workloads are not the same as traditional HPC workloads. Many HPC tasks can use weak scaling, and their communication patterns are relatively fixed. Large-model training requires more complex parallel strategies and more frequent synchronization. Model parallelism, tensor parallelism, pipeline parallelism, data parallelism, and expert parallelism all need to be coordinated. As MoE models, long-context models, multimodality, inference-time compute, and agentic workflows develop, communication patterns may become even more complex. The real challenge for a million-card AI system is not just scale. It is effective utilization under dynamic workloads.
Huawei’s bet in this direction is extremely aggressive. It is not just building chips. It is reimagining the scale of future AI infrastructure. Its implicit judgment is that if China cannot rely on Nvidia’s most advanced systems, then domestic compute must be built as data-center-scale infrastructure, not merely as a substitute for a single card or a single server.
This is why interconnect is the strategic core. Without interconnect, one million cards are just one million islands. With efficient interconnect, one million cards may become a system.
4. All-Optical Interconnects and the Software Stack Are the Two Gates Huawei’s System Route Must Pass Through
Another key element in Huawei’s interconnect route is all-optical interconnect. Traditional servers and short-distance connections can rely heavily on copper. Copper is low-cost, low-latency, and mature in deployment. But as bandwidth continues to rise, copper increasingly runs into problems of distance, power consumption, and signal integrity. Large-scale AI systems do not only need to connect multiple chips inside a server. They also need to connect large numbers of accelerators across cabinets, racks, and even wider data-center areas. At that point, optical interconnect becomes increasingly important.
One important feature of CloudMatrix 384 is that communication inside the system and between racks relies entirely on optical connections rather than traditional copper. Tom’s Hardware noted that CloudMatrix 384 uses a large number of 800G LPO optical modules to provide high-bandwidth, low-latency connections among 384 Ascend 910C chips. Atlas 950 SuperPoD goes further by adopting all-optical interconnects. Huawei’s official description states that all 160 cabinets in the full Atlas 950 configuration are connected through all-optical interconnects. This means optical interconnect is no longer just a small number of high-speed links. It becomes the foundational structure of the entire SuperPoD system.
The significance of all-optical interconnect has three layers.
First, it solves the distance problem. High-bandwidth electrical connections encounter more serious signal attenuation and power problems over longer distances, while optical connections are better suited for cross-cabinet, cross-row, and broader data-center-scale connections.
Second, it improves system scalability. When the number of chips expands from dozens to hundreds, thousands, and tens of thousands, the number of connections and bandwidth requirements rise rapidly. If the system still relies on traditional electrical connections, cabling, power consumption, and reliability all become extremely difficult.
Third, it turns Huawei’s industrial-chain position into an advantage. Huawei itself is a communications equipment company, with long accumulation in optical communications, switching equipment, network protocols, data-center networking, and telecom infrastructure. Nvidia’s advantage lies in GPUs and CUDA. Huawei’s advantage lies precisely in communications and system integration. For an AI compute route centered on interconnect, Huawei’s communications DNA is a very important asset.
Of course, all-optical interconnect also carries costs. The number of optical modules is enormous. Costs are high. Maintenance complexity is high. Fault detection and replacement mechanisms must be extremely mature. CloudMatrix 384 already uses thousands of optical modules. Atlas 950 and Atlas 960 will be larger still. Once the system enters the scale of ten thousand cards, or even hundreds of thousands of cards, the optical interconnect system itself becomes a huge operational object. Any connection failure, module abnormality, signal drift, or protocol issue may affect training stability. Therefore, the real challenge for Huawei’s route is not “whether it can lay optical links,” but whether it can turn all-optical interconnect into high-reliability, monitorable, maintainable, and scalable data-center infrastructure. Huawei’s telecom equipment experience can help, but AI training workloads have different requirements from traditional communication networks. Communication networks emphasize throughput, coverage, reliability, and quality of service. AI training also depends heavily on synchronization, low jitter, and deterministic performance. This is an engineering threshold Huawei must cross.
Interconnect is important, but interconnect is not omnipotent. A 16 PB/s or 34 PB/s interconnect system will still waste hardware bandwidth if the software stack cannot partition models correctly, schedule communication efficiently, optimize operators, handle failures, and remain stable during long training runs. The effectiveness of an AI compute system ultimately depends on the closed loop between hardware and software. This is also the hardest part of Nvidia to replicate. Nvidia’s interconnect is not powerful only because NVLink or InfiniBand is powerful in hardware. It is powerful because NCCL, CUDA, PyTorch, Megatron-LM, TensorRT, and other software layers have already packaged those hardware capabilities into tools that developers can use. Developers do not need to write communication algorithms from scratch or handle every low-level detail themselves. The ecosystem has absorbed the complexity.
Huawei does not yet have this depth of ecosystem. CANN, MindSpore, Ascend-version PyTorch, and ModelArts are improving, but they remain far behind CUDA in maturity, community scale, library richness, and tuning experience.
The core issue for the Ascend software ecosystem is this: hardware may initially provide “usable” compute, but whether it becomes “easy-to-use” compute depends on CANN operator coverage, compiler optimization, mainstream framework adaptation, developer migration costs, and debugging-tool maturity. This is the second constraint on Huawei’s interconnect route. Connecting 8,192 NPUs in hardware is only the first step. Making model training truly consume that interconnect domain through software is the second step. For inference, this may be relatively easier. Inference can be service-based, standardized, quantized, and containerized, and many application developers do not directly face the hardware. For industry fine-tuning, it is also more feasible because models are smaller, tasks are more fixed, and migration costs are more manageable. But for frontier large-model pretraining, the difficulty rises by multiples.
Frontier training requires long-duration stable operation, complex parallel strategies, data pipelines, optimizers, checkpoints, fault-tolerance mechanisms, mixed precision, communication scheduling, and operator libraries to work together. A single underperforming operator, an unstable communication pattern, or an incompatible framework version can reduce the utilization of the entire system. So Huawei’s interconnect bet must ultimately become a software bet. UnifiedBus provides the possibility. CANN and upper-layer frameworks determine whether that possibility can become effective compute. This is the boundary this essay must emphasize: Huawei’s interconnect route is very important, but it is not final victory. It provides a path around the single-chip gap, but for that path to truly work, it must depend on long-term refinement of the software ecosystem and real training workloads.
Every form of system-level compensation has costs. Huawei’s interconnect route has three main costs.
First, the energy-efficiency cost. CloudMatrix 384 already shows clearly that Huawei can use more chips, a larger memory pool, and a stronger interconnect domain to approach or even exceed some GB200 NVL72 system-level metrics. But system power consumption is much higher. Nvidia’s energy-efficiency advantage remains very clear. In the long run, energy efficiency affects data-center construction costs, power supply capacity, cooling design, and operating costs. China has relatively abundant electricity, and some regions have lower electricity prices, but that can only ease the problem. It cannot make the problem disappear.
Second, engineering complexity. A system like Atlas 950, with 160 cabinets, 1,000 square meters, all-optical interconnects, and 8,192 NPUs, is not something ordinary enterprises can easily deploy and operate. It requires customized data-center space, power supply, liquid cooling or other high-efficiency cooling systems, optical-module maintenance, communication-rack management, fault diagnosis, and deep Huawei support. The larger the system, the higher the system complexity. Complexity itself is a cost and a risk.
Third, ecosystem closure. Nvidia’s ecosystem is commercially tied to CUDA, but it has also become a de facto standard in the global developer community. Huawei’s ecosystem will more likely serve Chinese domestic customers, telecom operators, government and enterprise clouds, and strategic industries first. It may be more controllable, but also more closed. It may better serve domestic supply-chain security, but it will be harder to attract the global open-source community to adapt voluntarily. It may be more suitable for policy-driven adoption and large-customer customization, but harder to become the natural default platform for global developers.
These costs are real. Huawei’s route is not an easier route. It is a heavy system route forced into being by external constraints. It may be more power-hungry, more complex, and more dependent on large-scale capital expenditure and state-level demand pull. But under conditions where Blackwell, Rubin, and other advanced systems cannot be reliably obtained, it may still be China’s most realistic route. This is the realism of technological competition: if the optimal solution is unavailable, a second-best solution becomes extremely important as long as it can be deployed, iterated, and controlled.
5. The Essence of Interconnect Architecture Is to Bring China’s Strengths into AI Compute Competition
Huawei’s bet on interconnect is not accidental. It brings China’s relative strengths into the competition over AI compute. China is constrained in the most advanced GPU process technologies, HBM supply, EDA, advanced packaging, and the CUDA ecosystem. But China is not weak in power infrastructure, data-center construction, optical communication equipment, system integration, telecom operator networks, engineering deployment, and domestic demand organization. Huawei itself is one of the strongest communications equipment companies in the world, with long accumulation in optical networks, switching equipment, protocol engineering, reliability design, and large-scale network operations. If AI compute competition remains confined to the single chip, Huawei is at a disadvantage. If AI compute competition expands into system organization, Huawei can bring communications and system-integration capabilities into the battlefield. If the competition further expands into data centers, cloud services, government and enterprise deployment, industry applications, and domestic substitution, then the strengths of the broader Chinese system enter the battlefield as well.
This is the most important point to observe from the China as a System framework. Huawei is not building a chip in isolation. It is organizing communications capabilities, server capabilities, cloud capabilities, software capabilities, government and enterprise customers, telecom operator networks, and domestic supply chains into one system. This system may not be more efficient than Nvidia’s. It may not naturally win in a fully open global market. But it can continue iterating inside the Chinese market and policy environment. This is precisely the counter-effect of U.S. export controls that is hardest to manage. Restricting the most advanced chips does raise the cost of China’s AI training, reduce energy efficiency, and increase engineering difficulty. But it also forces Chinese companies to turn their attention toward domestic systems, creating real demand for Huawei Ascend, UnifiedBus, CloudMatrix, Atlas SuperPoD, CANN, and ModelArts. Real demand creates real problems. Real problems drive real optimization. This is not a story about surpassing Nvidia in the short term. It is a story about the formation of a substitution system.
The final test of Huawei’s interconnect bet is whether developers and model teams are willing to keep using it. If a system is very powerful but only Huawei engineers can tune it properly, it remains a heavy capital project, not an ecosystem platform. If a SuperPoD requires extensive customized optimization just to run one model, it can serve a small number of strategic customers, but it will struggle to become broad AI infrastructure. If CANN and PyTorch on Ascend cannot make model migration sufficiently smooth, many private AI companies will still try to use Nvidia, or other platforms with better compatibility, whenever possible. Therefore, Huawei’s next-stage task is to encapsulate the complexity of interconnect architecture downward and open system capability upward. Developers should not have to confront UnifiedBus details every day, just as Nvidia developers do not need to deal with every low-level detail of NVLink and InfiniBand every day. A truly successful platform turns bottom-layer complexity into a stable, predictable, high-performance developer experience.
This requires Huawei to keep advancing in three directions.
First, operator libraries and compilers must become more mature. Long-tail operators in large-model training and inference, attention mechanisms, MoE routing, long-context optimization, KV cache management, and multimodal operators all require deep optimization.
Second, distributed-training frameworks must become more reliable. At the ten-thousand-card level, the greatest risk is not whether a system can run fast once, but whether it can remain stable for long periods. Checkpointing, fault tolerance, failure recovery, communication scheduling, resource isolation, and performance monitoring all need to reach engineering-grade maturity.
Third, open-source ecosystem adaptation must become more active. If Huawei only pushes MindSpore, it will struggle to change developer habits. It must continue supporting PyTorch, vLLM, SGLang, Triton-like tools, mainstream open-source models, and inference frameworks, so that developers can minimize migration costs.
These three directions will determine whether UnifiedBus can evolve from hardware interconnect into ecosystem interconnect. Only when developers do not need to understand all the underlying complexity, and can still obtain stable performance, will Huawei’s SuperPoDs become a scalable platform rather than customized engineering projects for a small number of large deployments.
Huawei’s AI compute route cannot be summarized as “stacking weaker chips.” A more accurate description is this: Huawei is using interconnect as the strategic entry point, turning the single-chip gap into a systems-engineering problem through larger scale-up domains, larger memory pools, all-optical interconnects, UnifiedBus, SuperPoD, and SuperCluster. CloudMatrix 384 has proven the first-stage possibility: 384 Ascend 910C chips, connected through all-optical interconnects and an all-to-all topology, can form a system-level compute object comparable to GB200 NVL72. Atlas 950 SuperPoD pushes this logic to 8,192 Ascend 950DT chips, 1,152 TB of memory, and 16 PB/s of interconnect bandwidth. Atlas 960 and SuperCluster further show that Huawei is not trying to build a single product, but a domestic compute infrastructure for long-term AI competition.

This route still has obvious weaknesses. Single-chip performance is behind. Energy efficiency is behind. The software ecosystem is behind. Frontier-training validation is still insufficient. System complexity is very high. TCO may not be better than Nvidia’s. This is not a light, elegant route that global developers will naturally choose in an open market. It is a heavy system route under constrained conditions. But precisely for that reason, it reflects the real logic of China’s technological competition. China does not always begin with the strongest single-point breakthrough. It often begins with system organization, infrastructure, supply-chain coordination, engineering iteration, and domestic demand pull. Huawei Ascend’s interconnect architecture is exactly this logic applied to AI compute.
Nvidia’s core advantage is that it has turned the GPU into the standard engine of the global AI factory. Huawei’s core challenge is to turn domestically available NPUs under process constraints into the usable base of a Chinese AI factory. If this base eventually works, China’s AI compute competition will not be completely locked by the single-chip gap. It will enter another battlefield: who can better organize chips, memory, interconnects, electricity, software, cloud services, and industrial applications. This is Huawei’s interconnect bet. It is not betting that one chip can immediately catch Nvidia. It is betting that one system can keep narrowing the gap.
The next essay will turn to the third question: how China’s AI compute substitution will actually unfold. Real substitution will not mean replacing Nvidia everywhere overnight. It will advance layer by layer across inference, industry fine-tuning, mid-scale training, government and enterprise private deployment, cloud services, and frontier pretraining. Ascend may not immediately replace Nvidia’s frontier position, but it is very likely to become one of the core foundations of China’s domestic AI deployment.
This essay is part of China AI System Series. This series examines China’s AI development not as a narrow model race, but as a system-level competition involving chips, compute infrastructure, power systems, data centers, software ecosystems, industrial deployment, and state capacity. Future essays will continue to follow Huawei Ascend, UnifiedBus, CloudMatrix, Atlas SuperPoD, domestic AI chip substitution, AI electricity demand, low-cost inference, DeepSeek, and the broader formation of China’s second AI compute stack.
If you are interested in how AI is becoming a contest of industrial systems, infrastructure capacity, and global power, follow China as a System and subscribe for future essays in this series.
Thanks for doing this. Just one request: Given your prolific output it'd help if you can group in sequence the different components of your series. Readers like me would prefer to read them in sequence. Thanks again for your highly educative output!